File Masking
DATPROF Runtime not only enables data masking within databases but also supports the masking of external data files. This functionality allows you to apply the same masking rules used in database environments to (un)structured files, ensuring consistent and secure handling of sensitive information across your entire data landscape.
Using a masking template, Runtime interprets the structure of the file and applies the configured masking rules to the relevant data fields.
File masking is typically used in scenarios where:
Data files are exchanged between systems or teams.
Sensitive content is exported for testing, development, or analysis.
Compliance requires anonymization of personal or confidential information outside the database.
This functionality can be fully automated and integrated into your Runtime workflows, providing a streamlined approach to secure data handling across both databases and files.

Getting Started
This section helps you prepare your environment for creating and running DATPROF File applications. Once your environment is set up and directories are selected, you can proceed to Creating an Application.
Setting up the Environment
Before you can begin building a File Masking application, you'll need to create a group and add an environment.
File Masking Group
To add a new group, click the "New Group" button in the left menu under "Groups". Specify a name, such as "File Masking Demo".
File Masking Environment
After saving your group, you can now continue adding environments. An environment must be configured before you can start building application(s).
Click on the button "Add environment" and fill in a name for your environment. Select Files (Local, Azure) as the type.
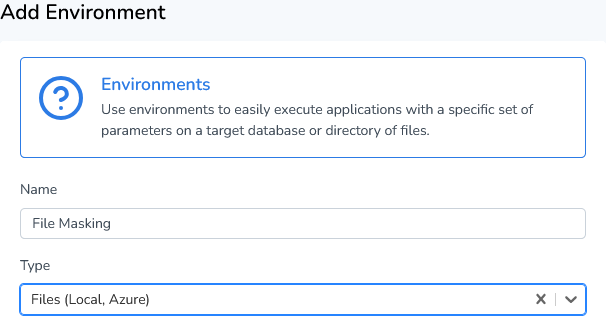
Runtime requires Input, Translation, and Output directories for File Masking. Verify directory paths by clicking the "Test connection" button. Currently, local, network, and Azure Data Lake Storage files can be masked. Support for AWS storage will be added in a future release.
Local/Network Files
Adding a Local/Network environment is straightforward. Enter the Input, Output and Translations files directory and press the “Test connection” button.
Ensure that Runtime has access to these locations. For example, using a local path such as C:\File Masking\Input means Runtime will look for this folder on the machine where Runtime is installed.
When referencing shared directories on the network, use the UNC path format (e.g., \\server\share\folder) or an IP-based path (e.g., \\192.168.1.10\share\folder).
Always verify that required network shares are reachable before testing the connection.
Azure Data Lake Storage Gen2
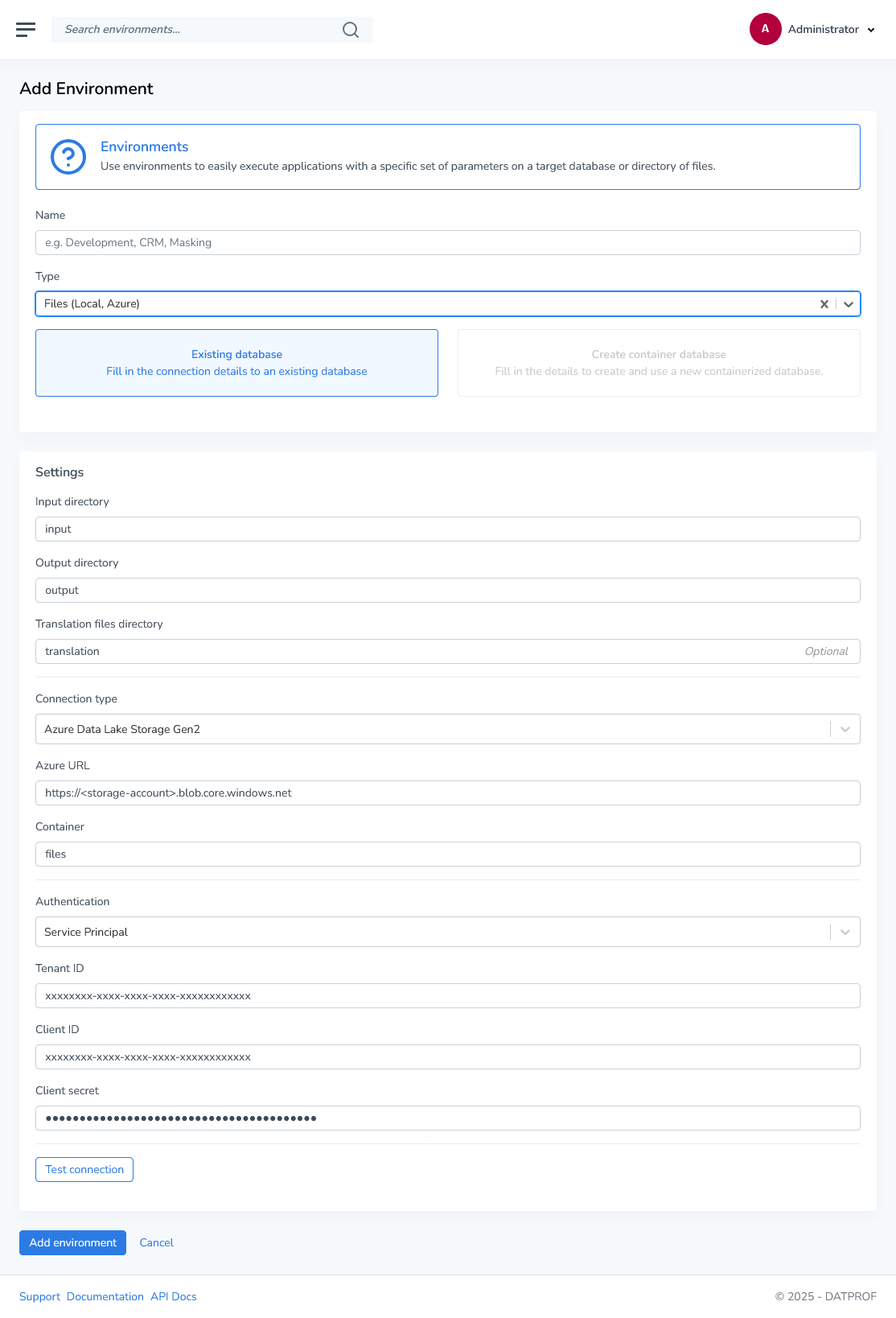
As of version 4.16.2, DATPROF Runtime supports file masking directly in Azure Data Lake Storage Gen2 environments, enabling cloud-native data masking workflows.
To configure Azure Data Lake Storage Gen2, begin by selecting it as your connection type from the available options. Next, choose your preferred authentication method from the three available options (Account Key, Service Principal, or Shared Access Signature Token).

Account Key
Required credentials: Storage account name and account key
Use case: Simple authentication for single storage accounts
Security note: Account keys provide full access; rotate regularly and store securely
Service Principal
Required credentials:
Tenant ID (Azure AD directory ID)
Client ID (Application/Service Principal ID)
Client Secret (Service Principal password/certificate)
Use case: Enterprise environments requiring role-based access control (RBAC)
Recommended permissions: Storage Blob Data Contributor role on the container or storage account
Shared Access Signature (SAS) Token
Required credentials: SAS token string
Use case: Time-limited, granular access with specific permissions
Security note: Configure appropriate expiration times and restrict permissions to minimum required (read/write on blob service)
Best Practice: Use Service Principal authentication for production environments to leverage role-based access control.
Enter the required credentials based on your selected authentication method, then specify the container and directory paths for your Input, Translation, and Output locations. Finally, click the Test Connection button to validate your credentials and verify directory access.
Once the group and environment are in place, you can proceed with defining the file structure, selecting masking rules, and configuring the masking template for your application.
AWS S3
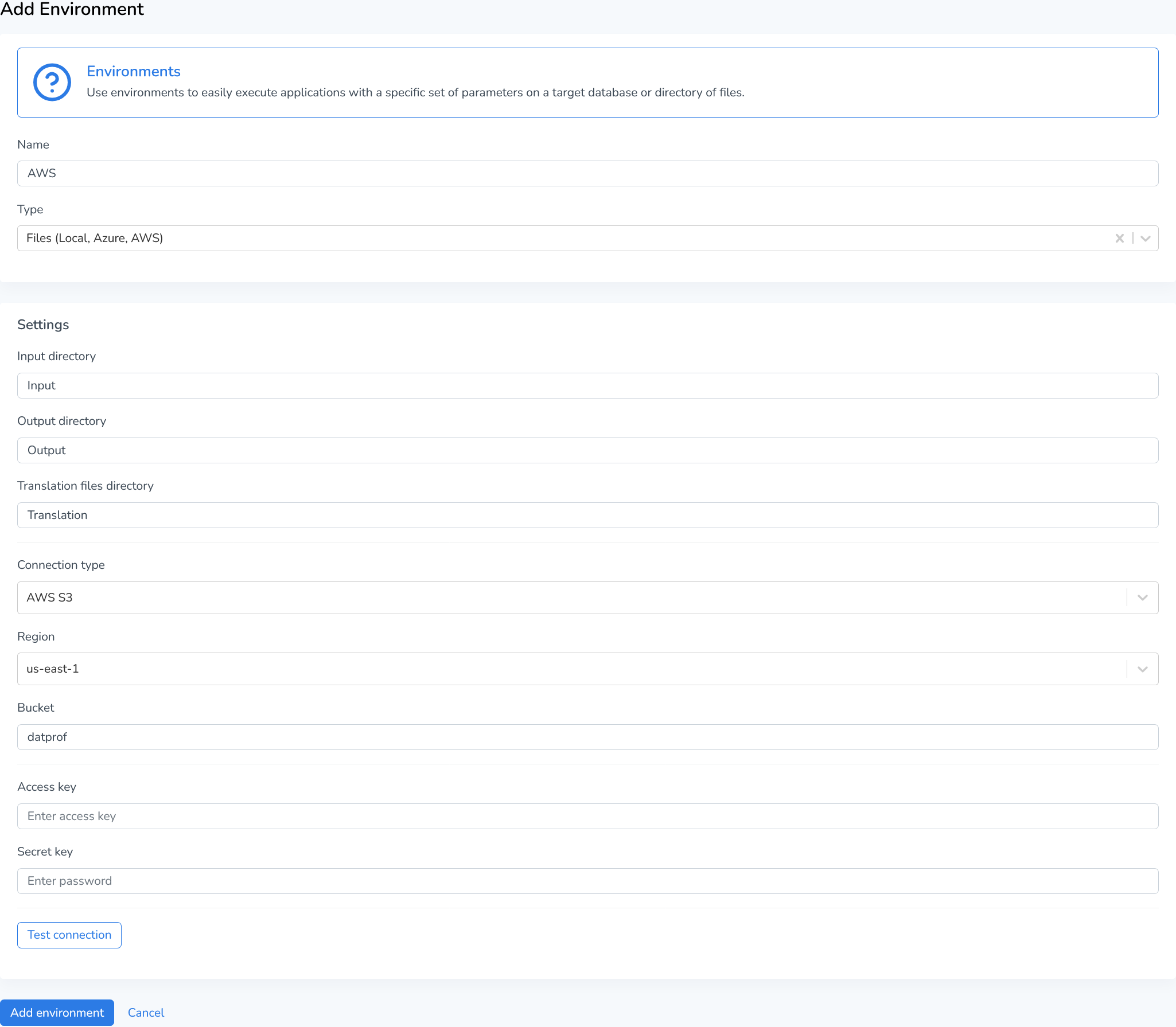
Starting with Runtime version 4.18.1, AWS S3 is supported as a storage backend. AWS S3 (Simple Storage Service) provides scalable, secure, and highly durable object storage. By integrating S3 with Runtime, you can leverage cloud storage for your applications while maintaining the flexibility and reliability that AWS offers.
Configuring AWS is easy, just select the region, enter the bucket name, provide an access key and secret key and test the connection!
Ensure the bucket already exists in your AWS account before configuring Runtime. Runtime will not create buckets automatically.
Region
Specify the AWS region where your S3 bucket is located. The region determines the physical location of your data and can affect latency and compliance requirements. For example,us-east-1oreu-west-1Bucket
Enter the exact name of your S3 bucket. Bucket names are globally unique across all AWS accounts and must follow AWS naming conventions (lowercase letters, numbers, and hyphens only).Access Key
Provide your AWS Access Key ID, which serves as the username for API authentication. This credential identifies your AWS account and is used alongside the Secret Key to authenticate requests.Secret Key
Enter your AWS Secret Access Key, which acts as the password for API authentication. This key is paired with your Access Key to securely sign requests to AWS services.
After entering all required credentials, use the built-in connection test feature to verify that Runtime can successfully communicate with your S3 bucket. If the test fails, double-check your credentials, ensure the bucket exists in the specified region, and verify that your IAM user has appropriate S3 permissions.
Creating an Application
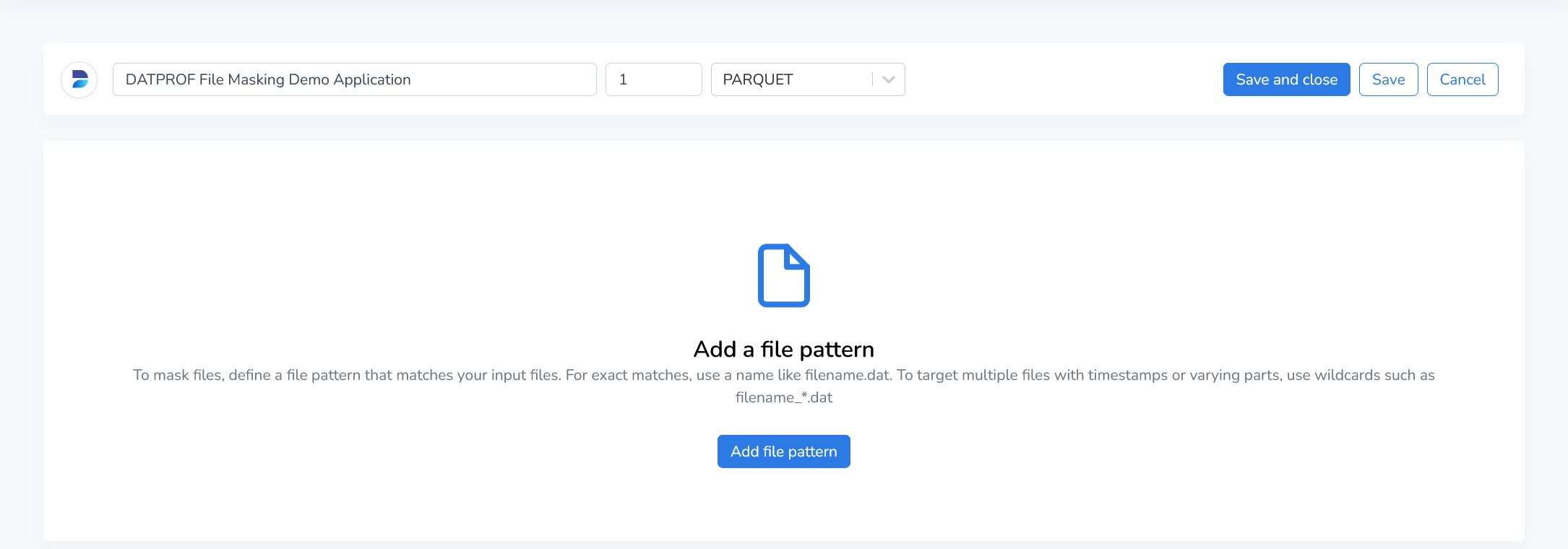
Once you’ve setup a group and environment, you can start with installing/building an application. You can do this by clicking “Install application” in the Environment overview and then selecting “Create a new application”. This will open the application editor:
The interface of the Application editor is quite intuitive, but we’ll walk you through the key features to ensure you get the most out of it. Start by entering the following information:
Name: Enter a unique and descriptive name for your application. This name will be used to identify your application within the DATPROF Runtime interface.
Version: Specify the version of the application you’re creating. Versioning helps you manage updates and track changes to your application over time.
File Type: Select the file type that you need to process. Currently, Parquet, CSV, XML, HFL and JSON Line (JSONL) files are supported.
Support for additional file formats will be introduced in future versions of DATPROF Runtime.
Once you’ve entered the application details, you’re ready to add file patterns and masking functions!
To configure the application for your file type, refer to the documentation in the left menu or in the section below.
JSONL Files
CSV Files
XML Files
Parquet Files
HFL Files
Masking and Generator functions
Runtime supports a variety of functions for File Masking. These functions allow you to apply a wide range of masking techniques, such as character replacement, data encryption, or randomization, to ensure that sensitive information is properly protected while maintaining the integrity and usability of the dataset. Whether you’re masking personal identifiers (PII), financial data, or other confidential information, DATPROF Runtime’s masking functions enable fine-grained control over how data is transformed.
This section will introduce you to the available masking functions for File Masking.
Masking
Masking Functions | Description |
|---|---|
Constant value | Creates a constant value in the generated dataset that is identical for every field. I.e. inputting MyFavoriteValue here will generate ‘MyFavoriteValue’ for every field in the resulting field’s dataset. |
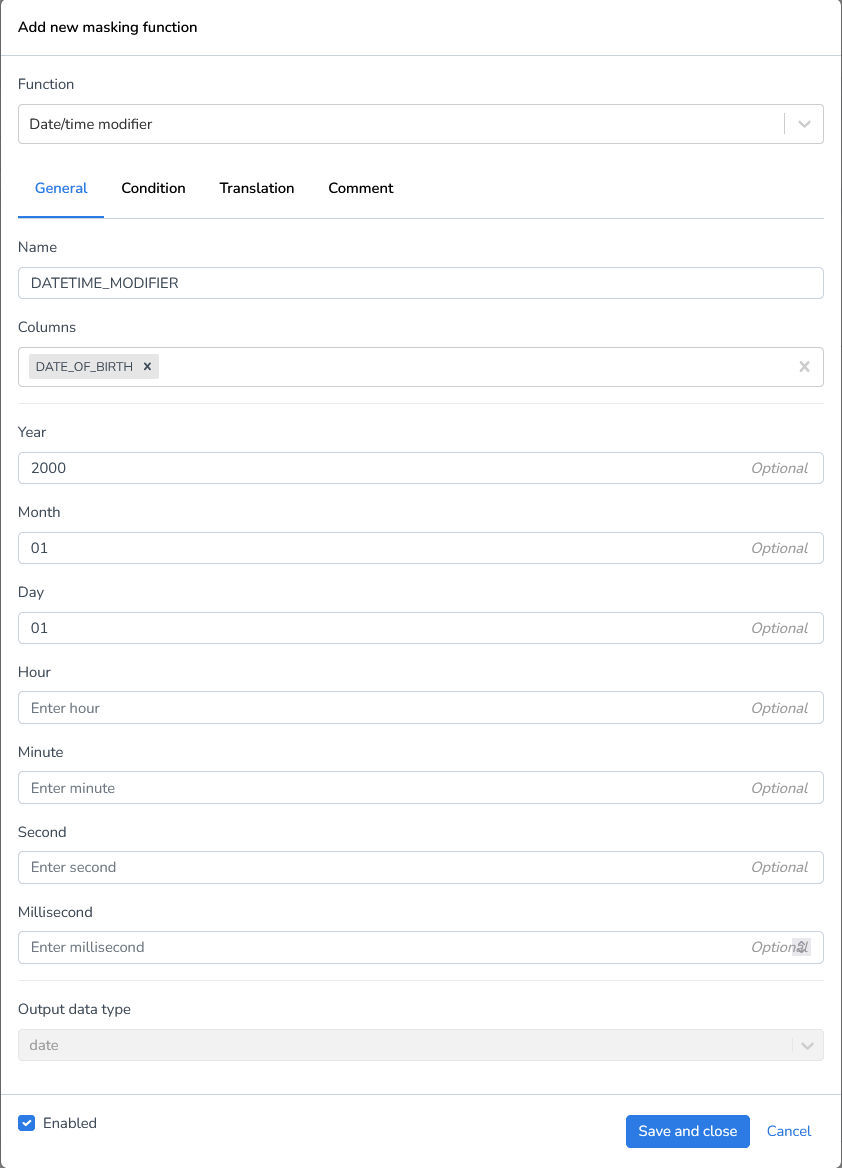
Date/time modifier | This function will change the existing date to a fixed day in the same month. Or to a fixed day in the first month of the same year. With this change, in most cases the new values remain functionally viable. |
Value lookup | With this function the replacement value will be obtained from a lookup file or translation file. |
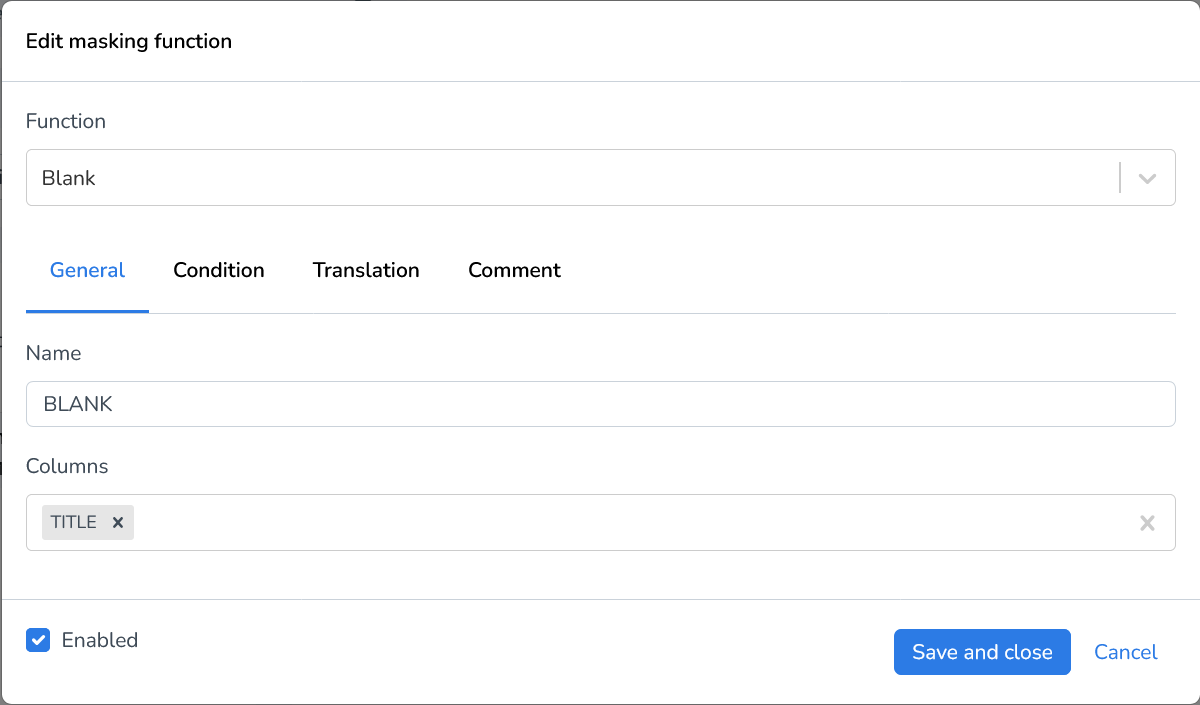
Blank | This function will NULL the selected field(s). |
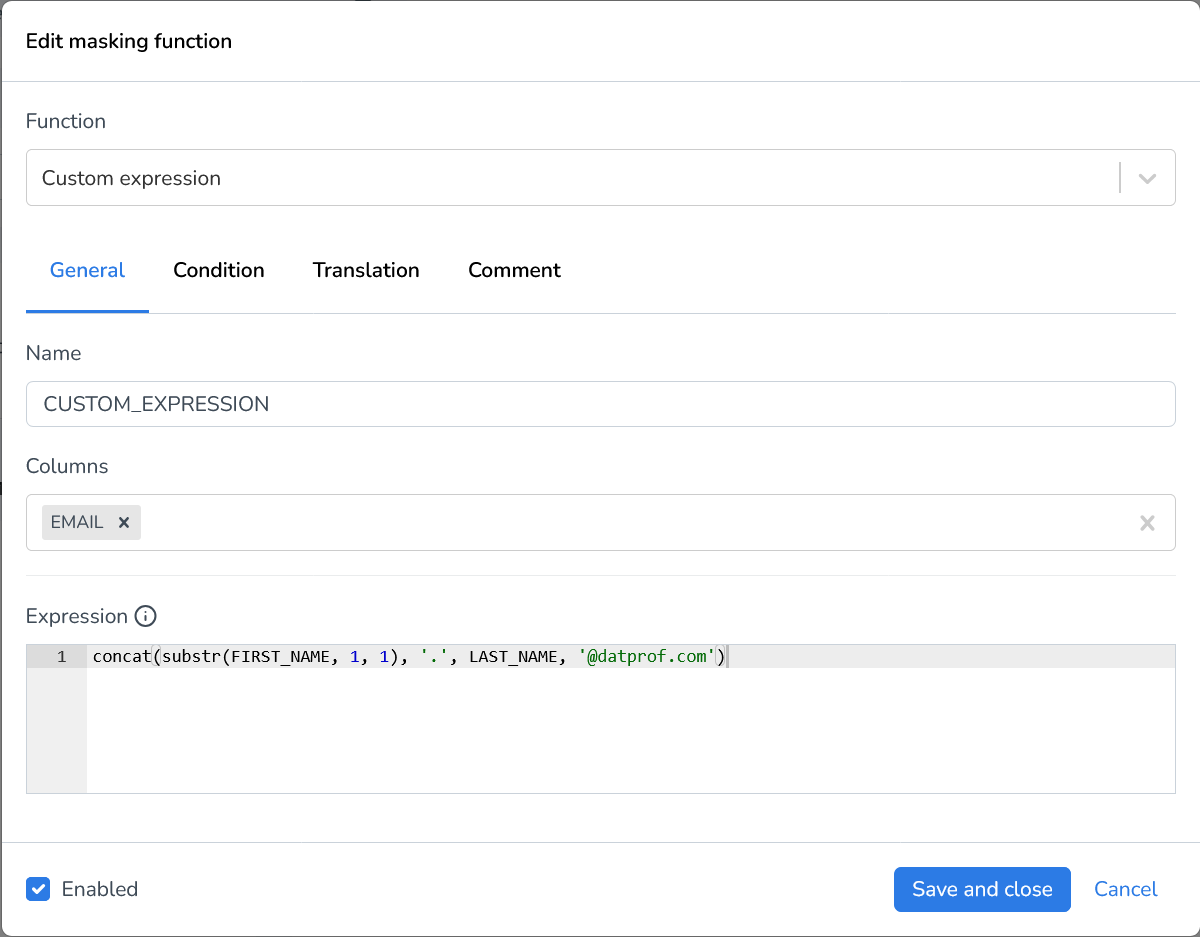
Custom expression | The Spark SQL custom expression should resolve to a value or contain a function that returns a value. |
Sequential number | Generates a sequential number for every field that starts at a specified value and increments by the step value per field. Additionally, you can define a Padding for your generated integers. This is a set number that will be affixed to the generated integer. For example, using a padding of 3, and a start of 8 with a step of 2 will generate the following: 008 → 010 → 012 |
Sequential date/time | Identical to the Random Date/Time generator except that this generator creates a sequential datetime for every field. Supplying a maximum datetime is optional. A number to increment the starting date is required, and can only accept whole numbers. Any unit of time to increment by can be chosen, from seconds to years. |
Basic Generators
Basic Generators | Description |
|---|---|
Random date/time | Generates a random Date/Time value per field between a specified minimum and maximum datetime that corresponds with the underlying field’s datatype. |
Random decimal number | Generates a random decimal number between a supplied minimum and maximum value for every field. Using the Scale setting the decimal accuracy can be defined. For instance, a generator with a minimum value of 0 and a maximum value of 1000 using a scale of 4 might generate 132.4202. |
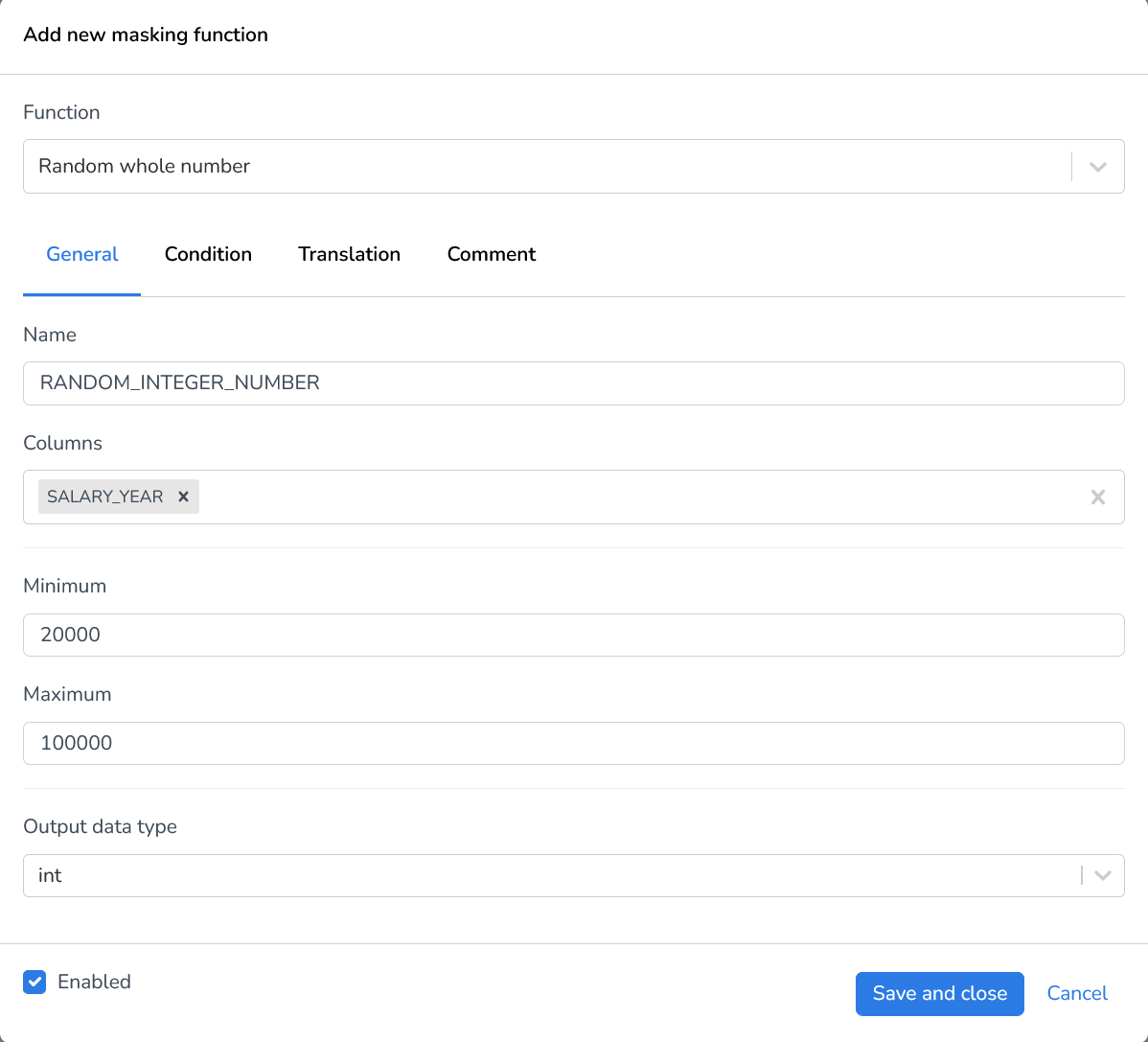
Random whole number | Generates a random integer between a supplied minimum and maximum value for every field. |
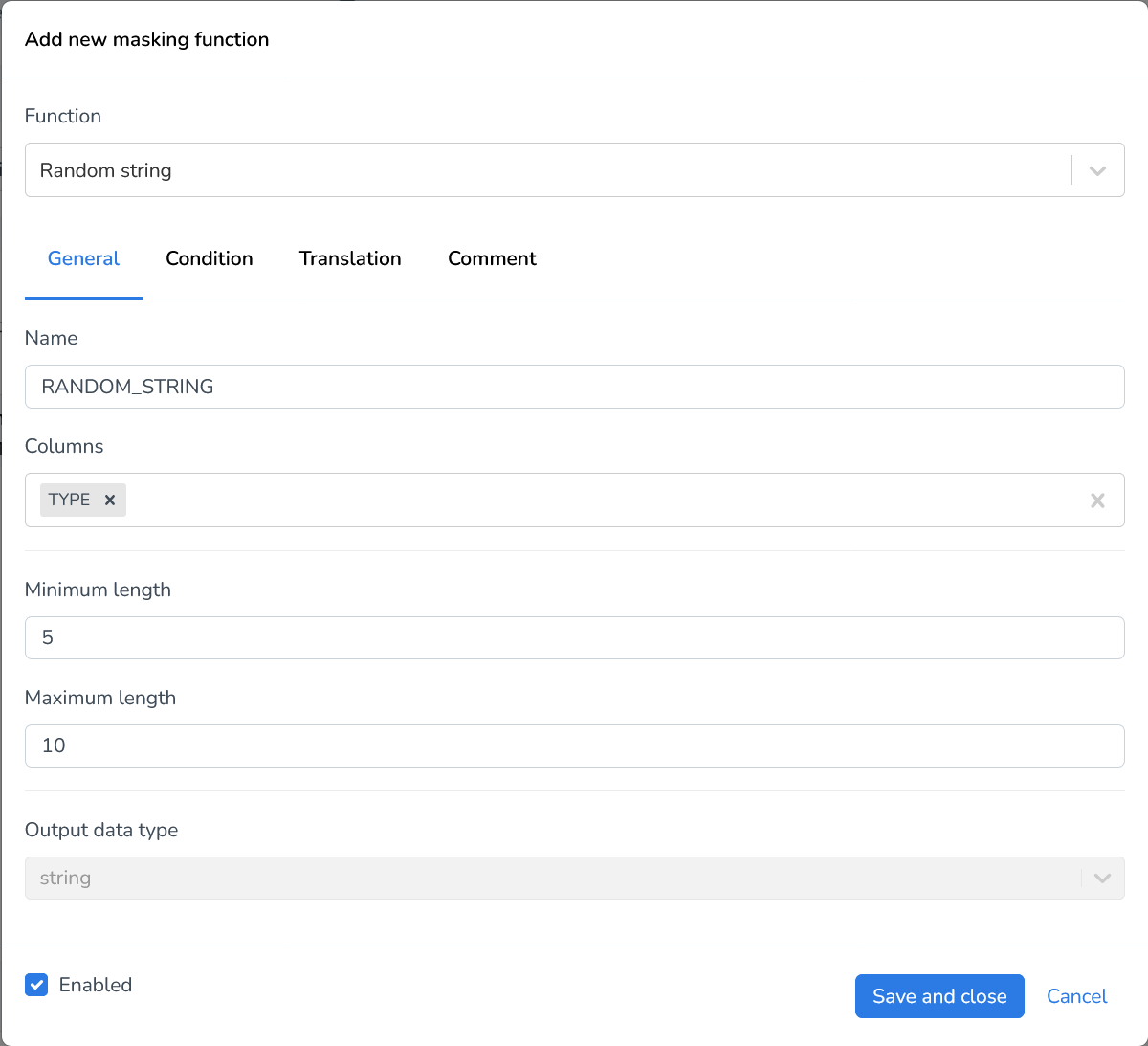
Random string | Generates a random string of lower- and uppercase letters for every field. The minimum and maximum length for strings can be defined. |
Business Generators
Business Generators | Description |
|---|---|
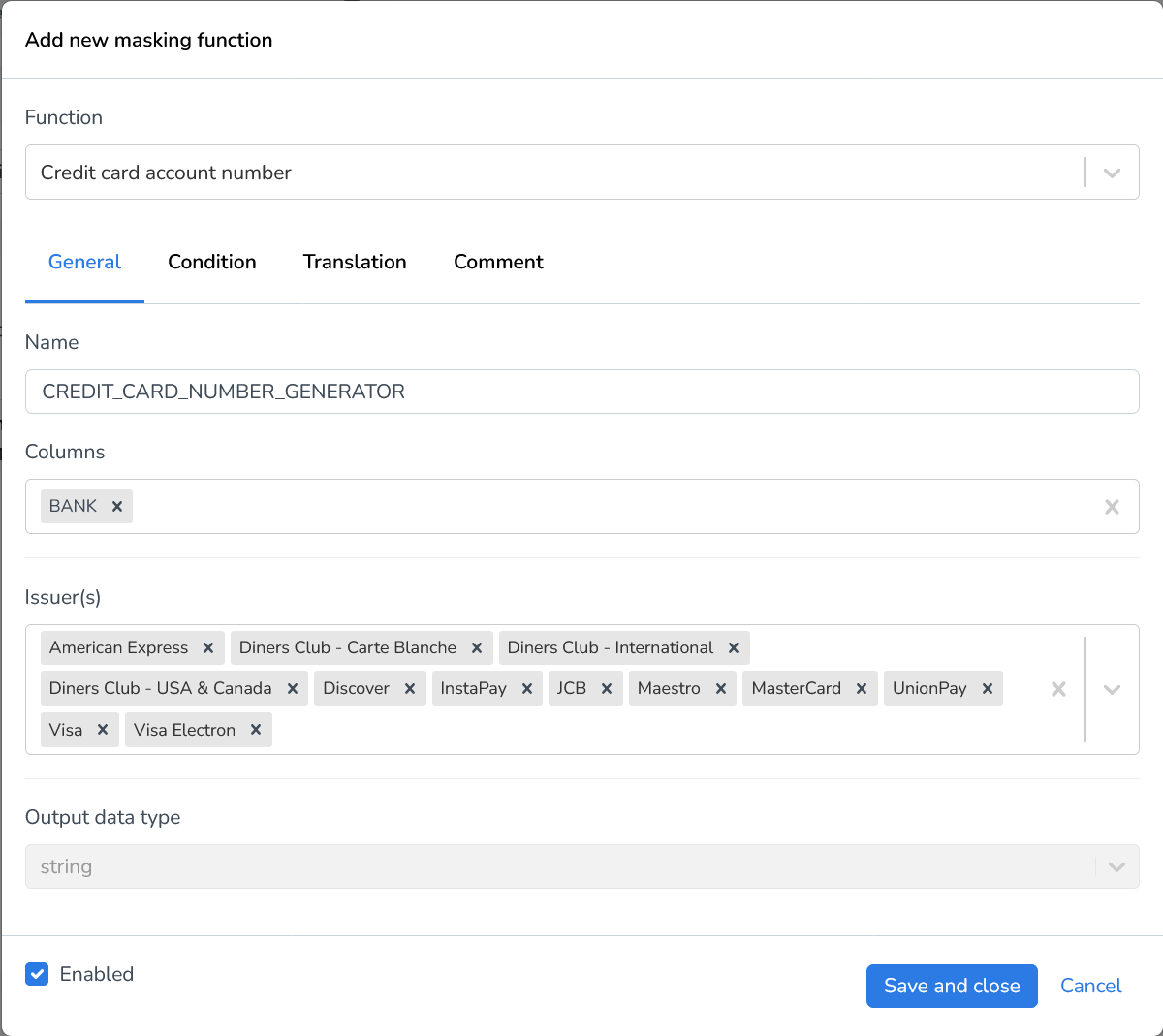
Credit card account number | Generates a random credit card account number. Using Issuer(s), you must define one or multiple issuers to determine which syntax the generated account numbers adhere to. |
IBAN (International Bank Account Number) | Generates a valid IBAN number for every field. Using Country Code(s) you can specify which country codes you’d like your resulting IBAN codes to use. |
Currency code | Generates a three letter currency code for every field. |
Currency symbol | Generates a currency symbol for every field. |
User agent | Generates user agents per field, for example: Mozilla/4.0 (compatible; MSIE 5.13; Mac_PowerPC), Opera/8.53 (Windows NT 5.2; U; en). |
A-Number/GBA Number (Dutch township security number) | Generates a 10 digit GBA number per field. |
Genre | Generates a media genre for every field. |
BSN Number (Dutch citizen service number) | Generates a valid Dutch social security number per field. |
SSN (US Social Security Number) | Generates a SSN for every field. You can specify how you want to separate your resulting numbers. You can choose one of the following formats:
|
Job | Generates a profession for every field. Using the Language(s) you can specify which language(s) you want your resulting job names generated in. |
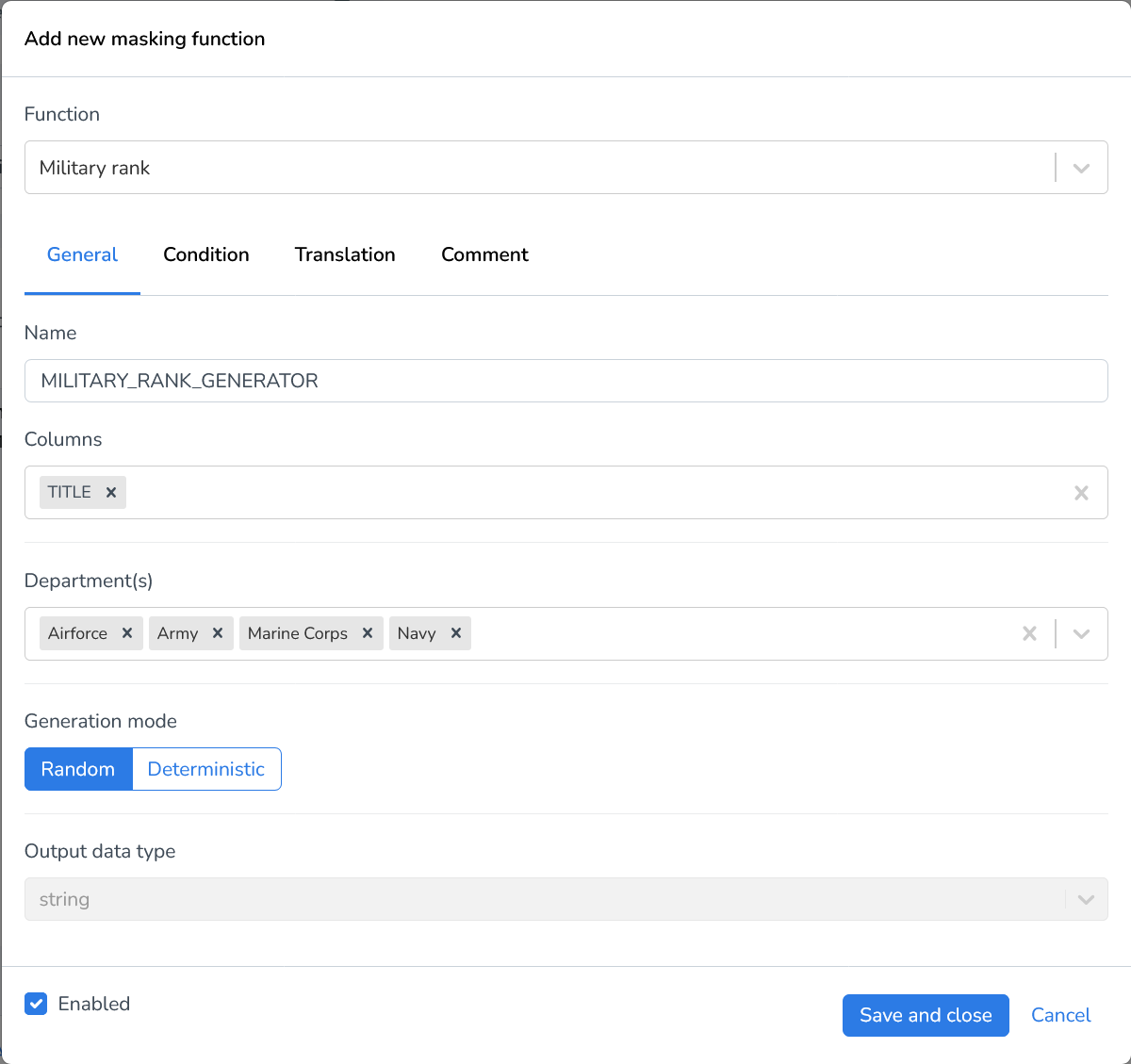
Military rank | Generates a military rank name for every field. Using Department(s) you can specify which branches of the armed forces you’d like to include in your resulting dataset. |
Advanced Generators
Advanced Generators | Description |
|---|---|
Regular expression | Generates values based upon a regular expression. The syntax for the regular expression used in Runtime/Privacy is specific to the package we use, so please refer to the specifications here. |
Name Generators
Name Generators | Description |
|---|---|
Brand | The Brand generator creates a unique brand name for each field in your dataset. It is particularly useful when working with data that requires distinct and realistic brand names. |
Color code | Generates a color hexcode (Both three-digit shorthand and six-digit full length hexcodes) per field. |
Color | Generates a random color per field. (Ex. Baby Blue, Sky Blue, Soft White) |
Dinosaur | The Dinosaur generator generates a Dinosaur name for each field in your dataset. |
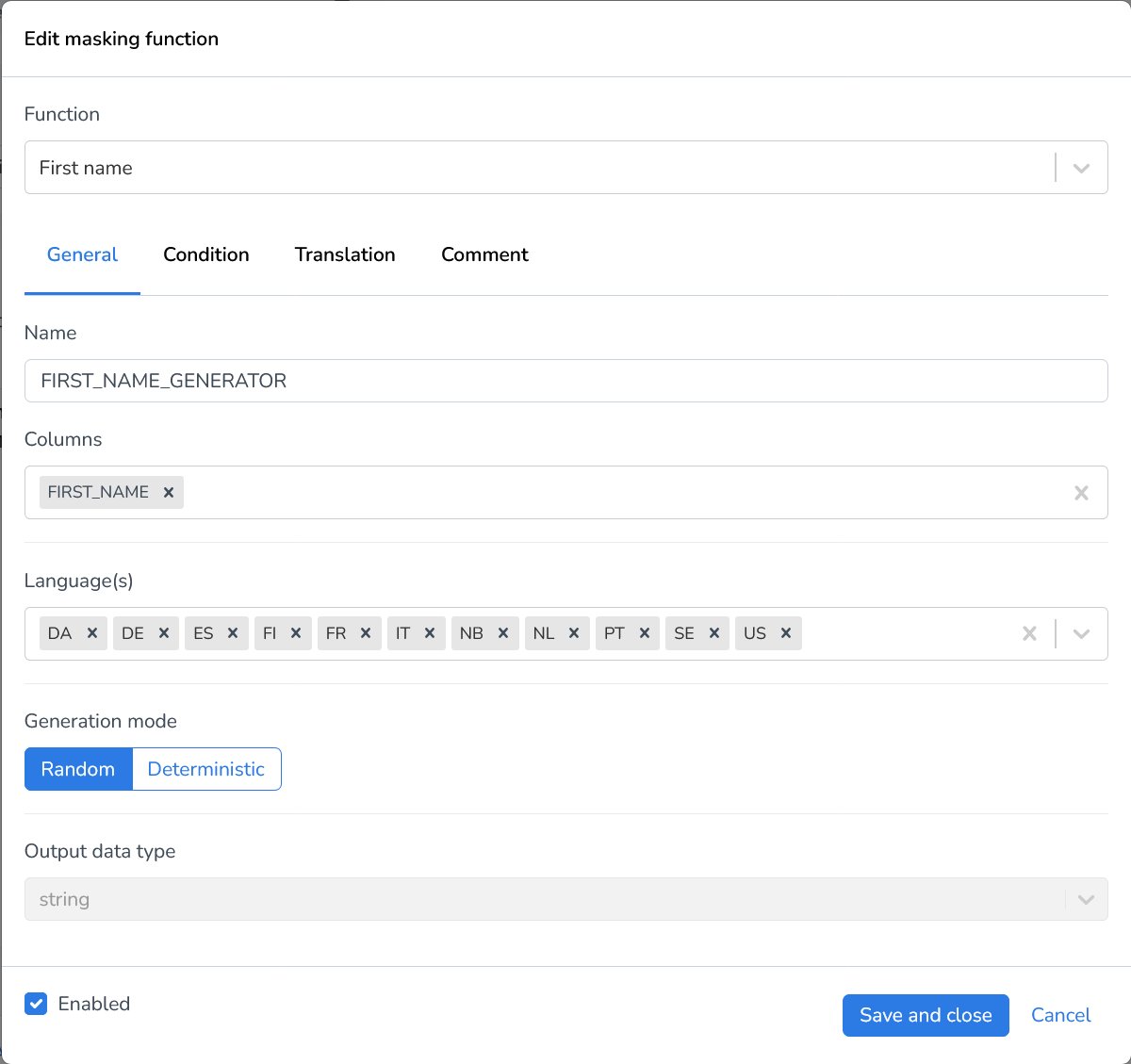
First name | The First name generator creates a unique first name for each field in your dataset. It is particularly useful when working with data that requires distinct and realistic first names. |
Full name | The Full name generator creates a unique full name for each field in your dataset. |
First name (female) | The First name (female) generator creates a unique female first name for each field in your dataset. |
First name (male) | The First name (male) generator creates a unique male first name for each field in your dataset. |
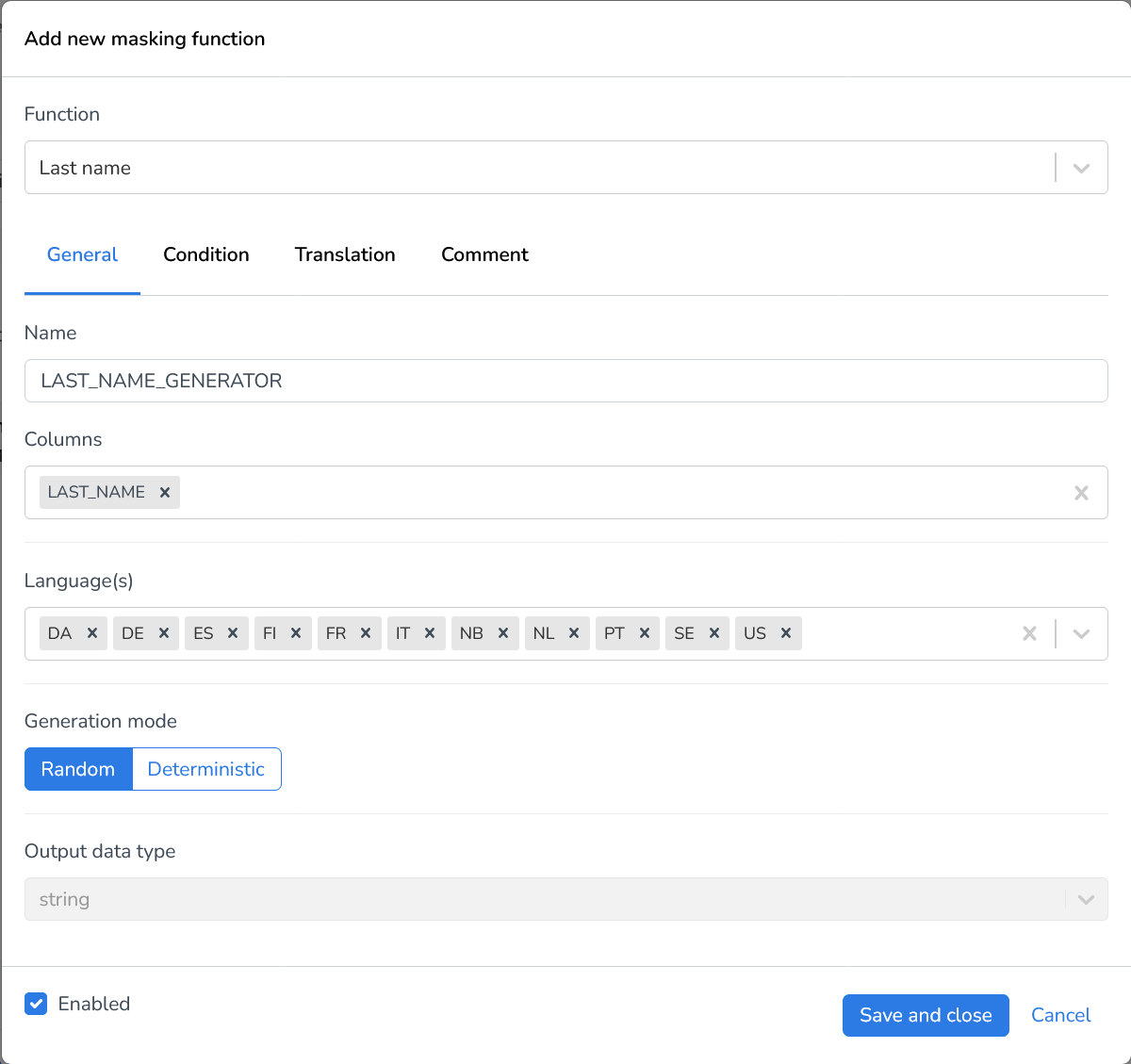
Last name | The Last name generator creates a unique last name for each field in your dataset. |
Random word | The Random word generator generates a random word for each field in your dataset. |
Location Generators
Location Generators | Description |
|---|---|
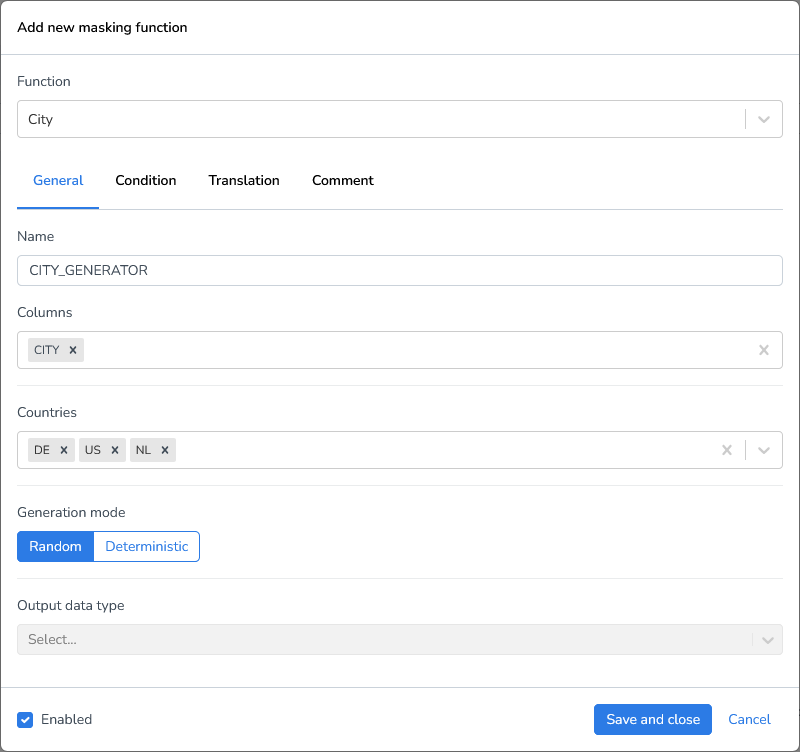
City | Generates a random city name per field. Here, you can specify for which countries you’d like to generate random names using the Countries drop-down menu. |
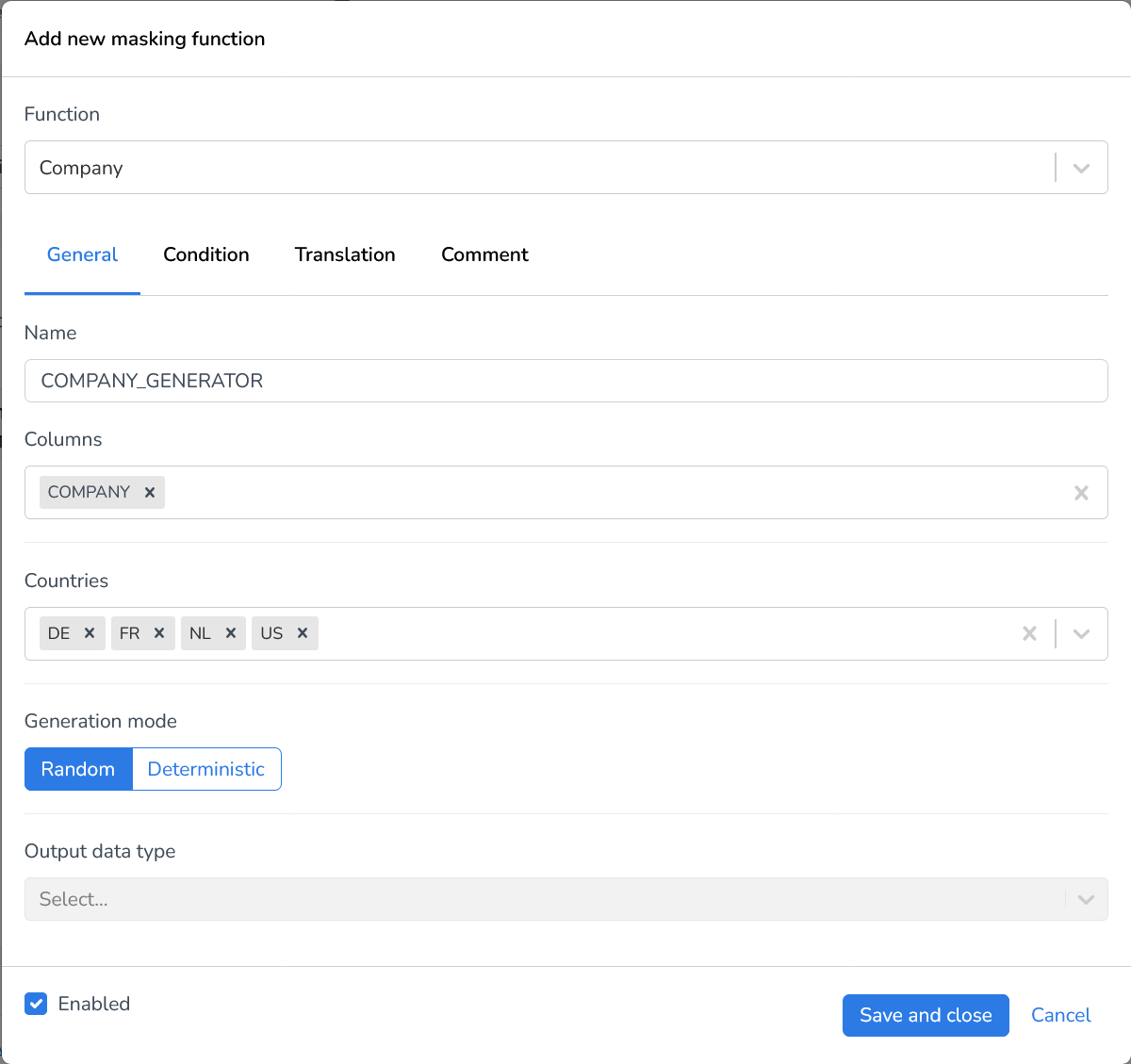
Company | The Company generator generates a random company name for each field in your dataset. |
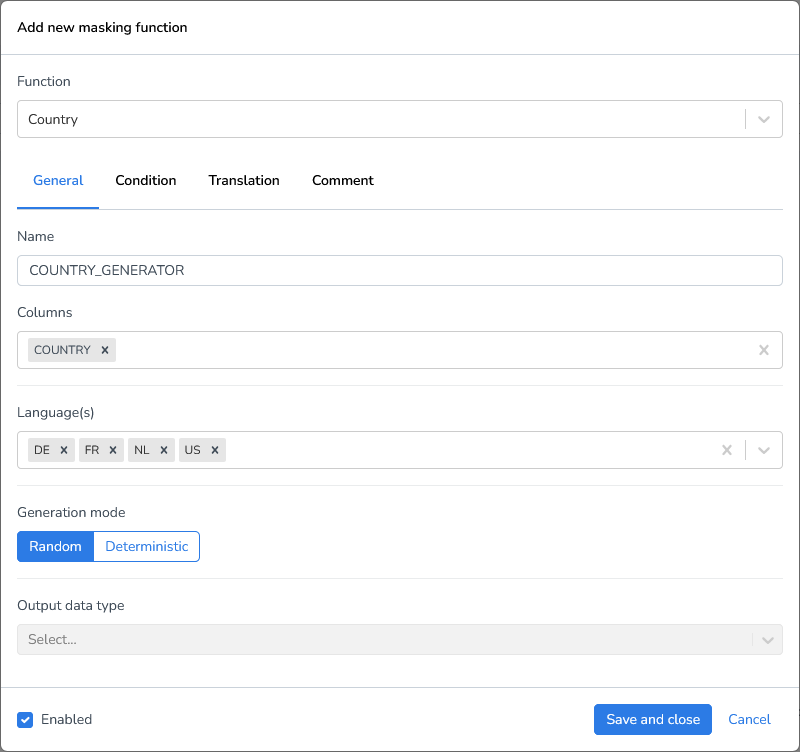
Country | Generates a random country name per field. The Language(s) option specifies in which language the country will be written. Multiple options can be enabled simultaneously. |
Street | Generates a random existing street name per field. The Countries option allows you to specify for which country street names will be generated. |
Two letter country code | Generates a random country code per field either in a 2 letter country code. |
Three letter country code | Generates a random country code per field either in a 3 letter country code. |
Advanced Settings
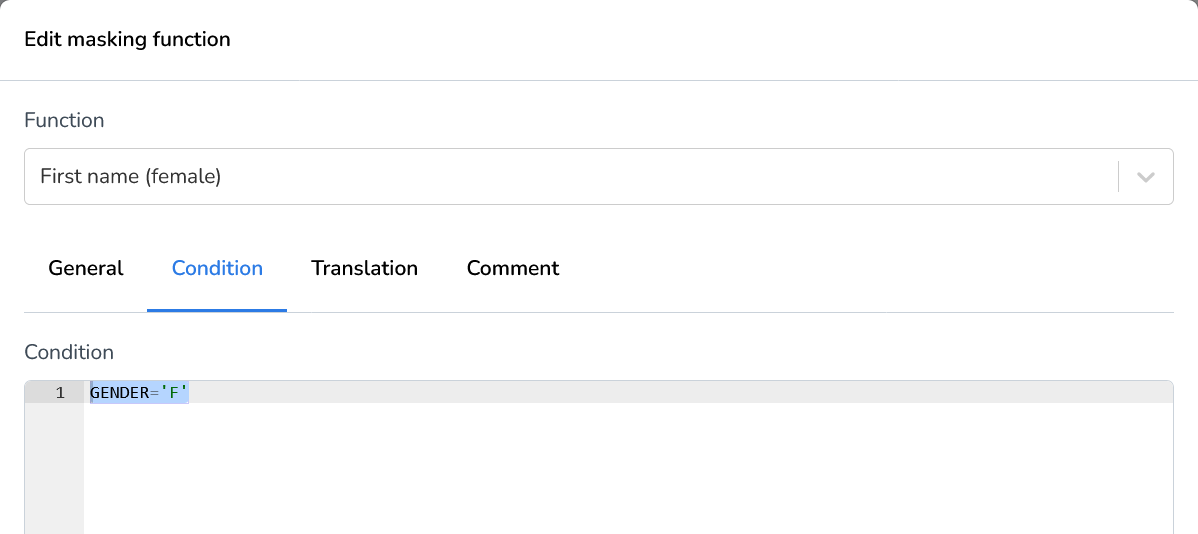
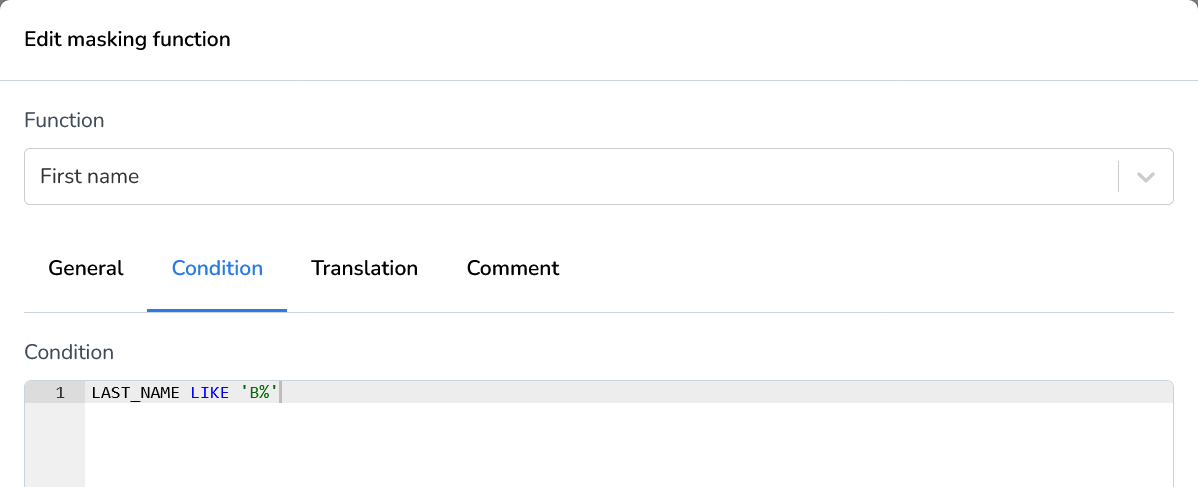
Condition
The Condition tab enables you to apply filters to the selected fields based on specific values. This allows you to define precise masking rules that apply only when certain conditions are met.
For example, in our demonstration, we’ll use the First Name (Female) generator to mask the selected field only when the gender field contains the value "F". This ensures that the masking function is applied selectively, preserving the integrity of other records while maintaining realistic and consistent data.
Translation
You can choose to store the result of the data masking function in a translation file. This is particularly useful in implementing consistent data masking between files. Translation files store the old and the new value for each field value in the file.
The Translation tab inside a masking function lets you create and name translation files:
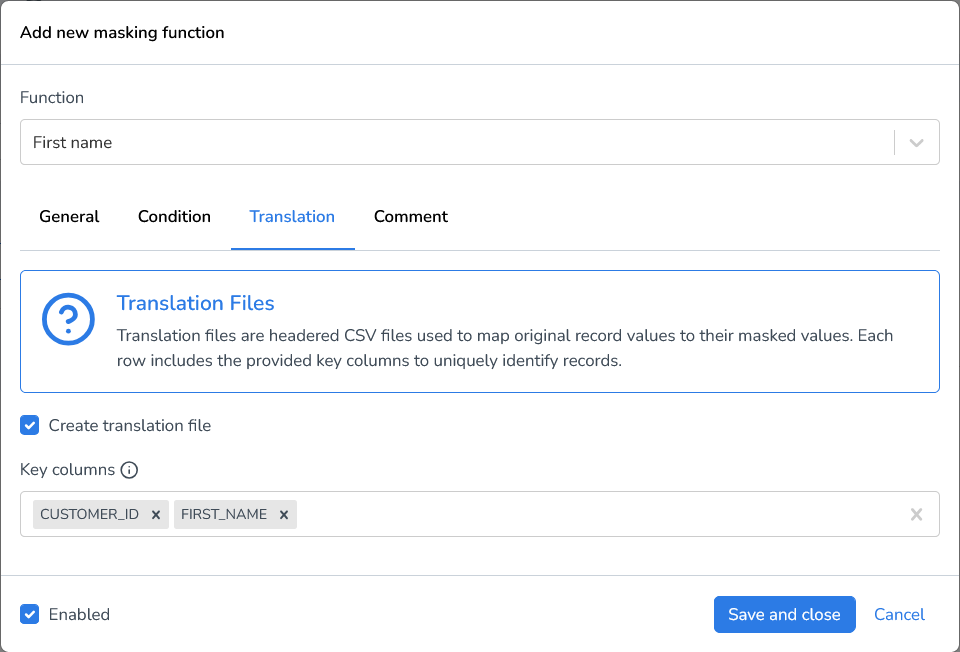
Note: Comma-separated list of columns that will be used as keys in the translation file. (e.g. id, customerId)
Comment
The Comment tab allows you to add internal notes or documentation related to your File Masking functions. This section is not used during execution but serves as a helpful space to provide context, instructions, or other information for yourself or team members.
Typical uses for the Comment tab include:
Describing the purpose or scope of the masking function.
Documenting important changes or version history.
Adding notes for future maintenance or handover.
Listing assumptions, known limitations, or special handling rules.
Providing clear and concise comments can improve collaboration and make it easier to manage and troubleshoot the application over time, especially in environments where multiple team members are involved.
Deploy and Run
Important note on attribute ordering:
When processing JSONL files, the order of attributes in each JSON object cannot be guaranteed. Attributes are written out alphabetically. This is not a problem for programs that read the data, it may appear unusual when inspecting the file manually.
Once you have created an application, you can deploy and run it to start masking your files. DATPROF Runtime provides two options: running the application directly or integrating it into automated workflows using the API.
Deploy Now
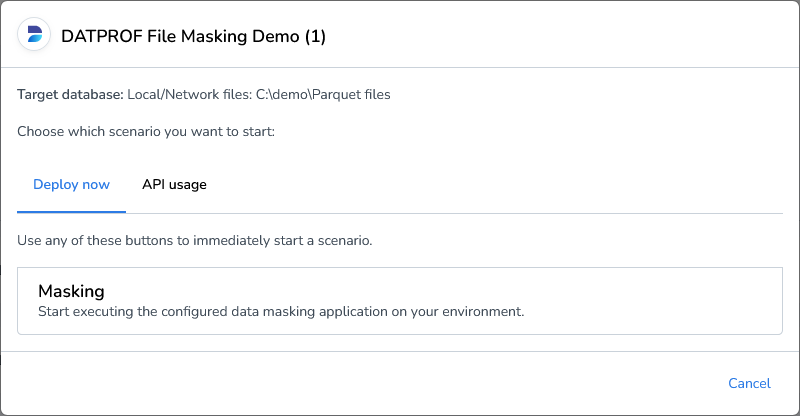
The Deploy Now option allows you to run your File Application immediately. This is the fastest way to check that your configuration is correct and that the masking process runs as expected.
Click “Start...” next to your application.
On the “Deploy now” tab, select Masking to start the application.
Monitor the execution and review the output in the target directory.
API Usage
For integration with other tools, scheduling, or automation, you can deploy and run your file masking applications through the DATPROF Runtime API. With the API, you can:
Trigger masking jobs from external systems.
Automate test data provisioning as part of CI/CD pipelines.
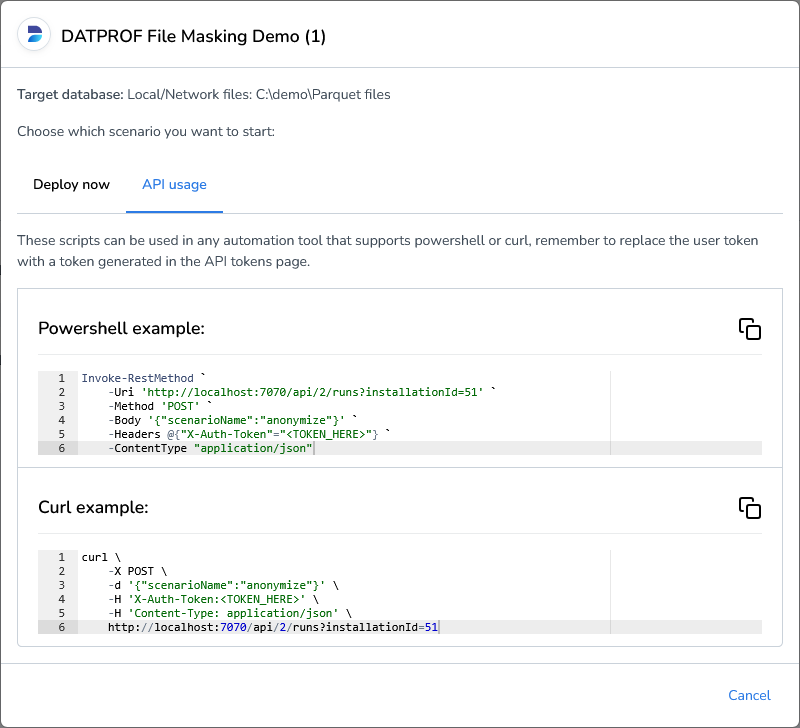
For more information on how to use DATPROF Runtime’s API, please refer to the Using the API section.