Direct & Runtime Deployment
There are two options to deploy your template. During development you can directly execute it from DATPROF Subset to the database inside the deployment center. When your template is finished you can also generate it as a Runtime application and upload and deploy it in DATPROF Runtime. Within DATPROF Runtime you can create multiple environments (target databases) and deploy the template from there. If you would like to know more about the general functionality of Runtime, please refer to the manual here
The Deployment screen allows the user to deploy the configured Subset directly to the database. By pressing Start the subset project will be generated and executed against the target database. During the run, the process can be paused or aborted using the Pause and Abort buttons.
The progress of the run can be followed inside the monitor and in the tab Logging. Information about which modules, its classification, source and target counts are shown in the monitor.
The tab Logging can be used to view the steps and the results of the individual actions. This logging might be useful for analyzing problems.
Direct Deployment & Legacy Deployment
With DATPROF Subset 4.0 comes a new standard approach in how a template is being executed. An Runtime agent is embedded in the DATPROF Subset 4.x installation and is being used as the default deployment method. This deployment mode is for each supported database available. The old pre 4.x deployment mode is still available for a short period of time under Project → Use legacy deployment. These code generators are deprecated.
Direct Deployment | Direct Deployment (legacy) | Runtime Deployment | |
|---|---|---|---|
Oracle | x | x | x |
MS SQL Server | x | x | x |
DB2 for iSeries | x | x | x |
DB2 for Linux, Unix, Windows (LUW) | x | x | x |
DB2 for z/OS | x | x | |
PostgreSQL | x | x | |
MySQL / MariaDB | x | x |
Deployment options
When running a Subset template, the deployment options can be altered by referring to the tabs located at the bottom of the deployment page.
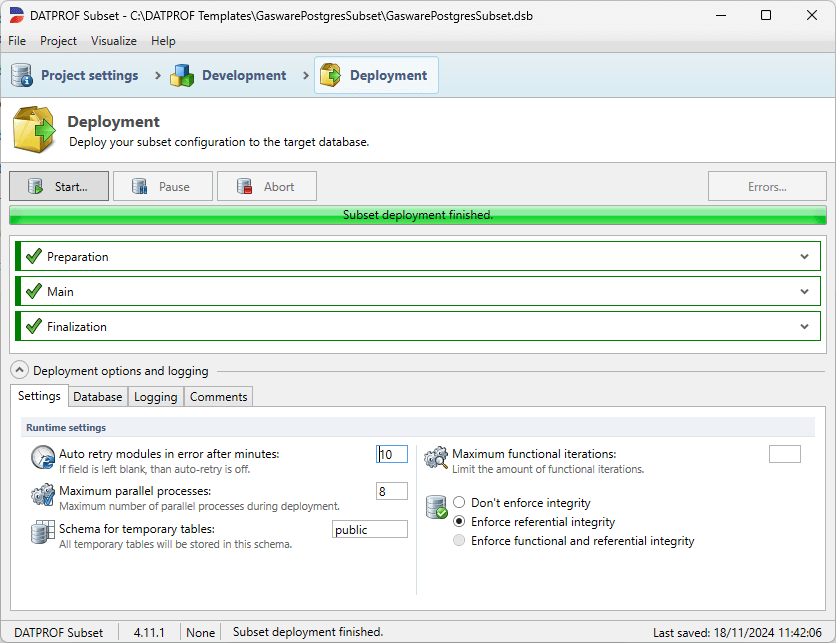
Settings
Several options are available to influence the execution of a Subset run.
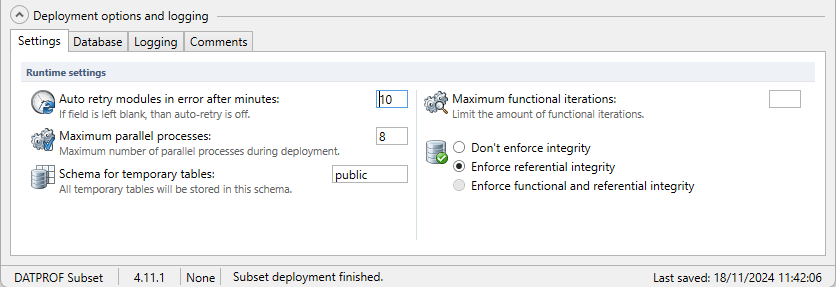
Runtime settings
Auto Retry modules in error after minutes: If specified a process will restart after the given time in minutes when it was stopped by an error.
Maximum parallel processes: This value specifies the maximum amount of parallel processes DATPROF Subset uses. The default is 8.
Maximum functional iterations: This values specifies the maximum number of Functional iterations allowed. When using large and complex models it might be necessary to limit this because the deployment time takes too long.
Schema for temporary tables: This option specifies the schema name to store the temporary tables. Default this is the Target Schema and this schema should be available in the Target database.
Deployment settings
Don’t enforce integrity: With this option enabled the Foreign Key relations are not validated. Missing “parent-records” will not be added. (No technical iteration). It is not recommended to enable this option.
Enforce referential integrity: With this option enabled all Foreign Key relations are validated and missing “parent-records” are added. (Technical iteration)
Enforce Functional and Referential integrity: With this option enabled all Foreign Key relations are validated and missing “Parent-records” are added. (Technical iteration).
Also all “Child-records” are added for Foreign Key relations which are classified as Functional Consistent (Functional iteration).
Settings (Legacy; enable under project - use legacy mode)
Several options are available to influence the execution of a Subset template.
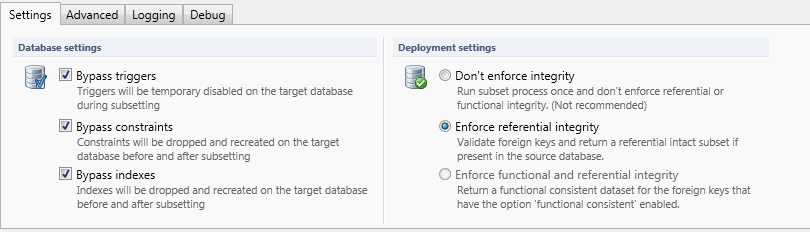
Bypass triggers: By default triggers are disabled at the beginning of the subset process. By un-checking this option triggers remain enabled. Enabled triggers may cause performance and data related problems.
Bypass constraints: With this option enabled all constraints (Primary, unique, referential) on the effected tables are dropped to avoid disturbing the Subset process. After successful subsetting they are re-created.
In a normal situation it is not recommended to preserve the constraints because this will impact the performance and may cause data errors.Bypass indexes: With this option enabled indexes are removed during the deployment. After successful subsetting they are re-created.
Un-checking this option slows down performance greatly.Don’t enforce integrity: With this option enabled the Foreign Key relations are not validated. Missing “parent-records” will not be added. (No technical iteration). It is not recommended to enable this option.
Enforce referential integrity: With this option enabled all Foreign Key relations are validated and missing “parent-records” are added. (Technical iteration)
Enforce Functional and Referential integrity: With this option enabled all Foreign Key relations are validated and missing “Parent-records” are added. (Technical iteration).
Also all “Child-records” are added for Foreign Key relations which are classified as Functional Consistent (Functional iteration).
Tab: Advanced (Legacy; enable under project - use legacy mode)
Some additional options are available which have effect on the Deployment process.
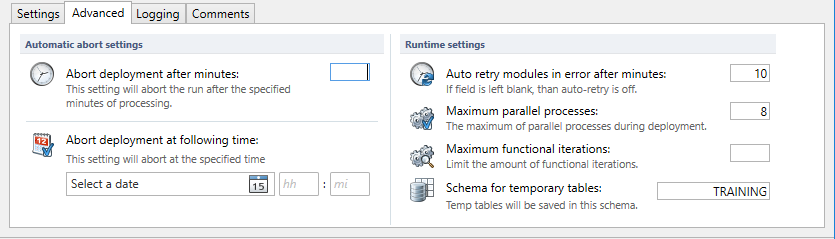
Abort deployment after minutes: If specified the deployment will abort after the given time in minutes.
Abort deployment after following time: If specified the deployment will abort at the given time.
Auto Retry modules in error after minutes: If specified a process will restart after the given time in minutes when it was stopped by an error.
Maximum parallel processes: This value specifies the maximum amount of parallel processes DATPROF Subset uses. The default is 8.
Maximum functional iterations: This values specifies the maximum number of Functional iterations allowed. When using large and complex models it might be necessary to limit this because the deployment time takes too long.
Schema for temporary tables: This option specifies the schema name to store the temporary tables. Default this is the Target Schema and this schema should be available in the Target database.
Tab: Logging
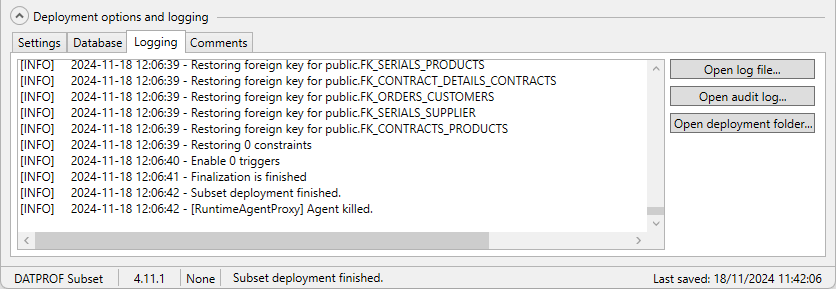
The tab Logging shows the information of the last Deployed Subset process.
This information can be exported to a text file by pressing Export…
To open the location of all the log files, press Deployment Folder (not available in legacy deployment mode)
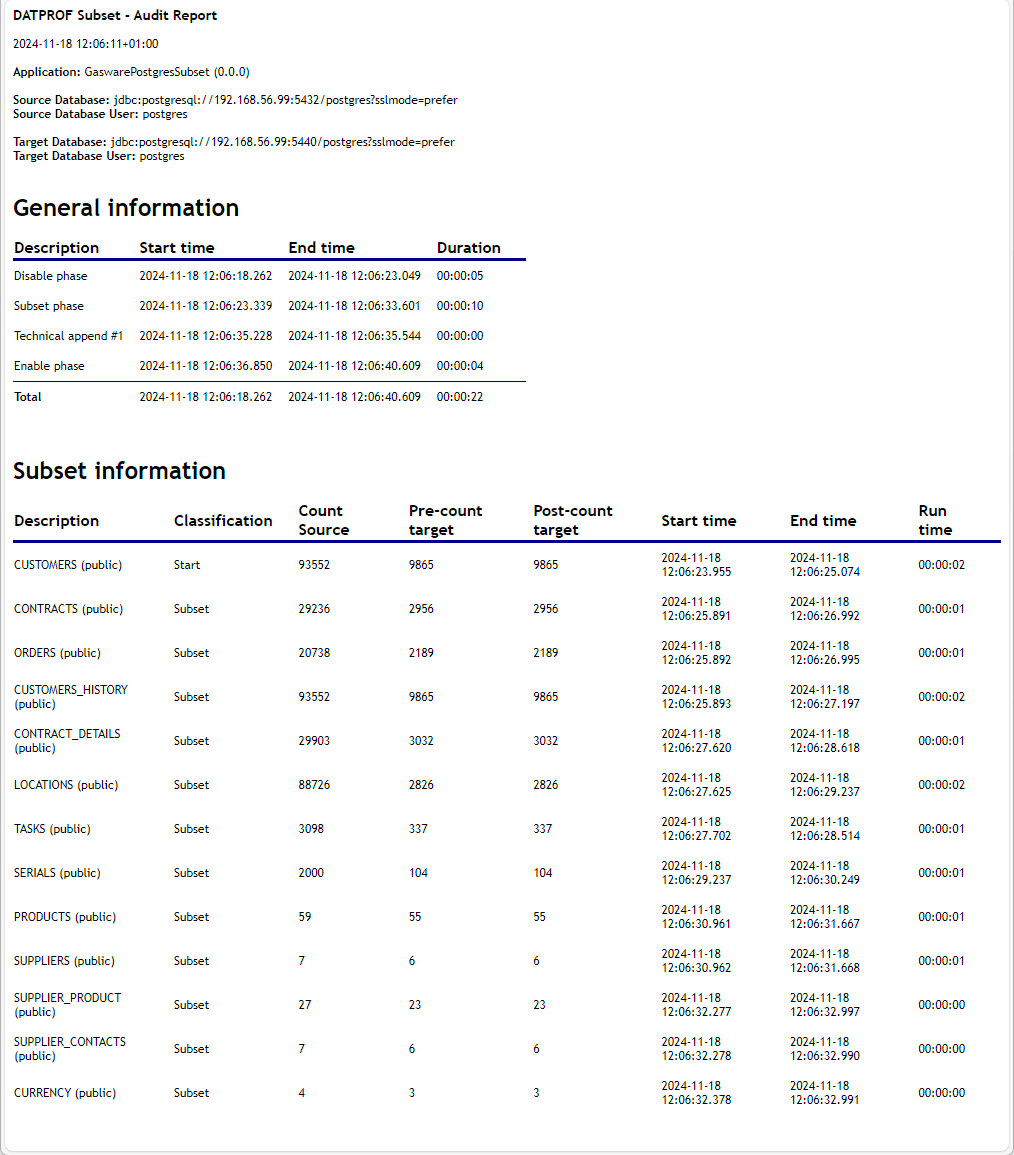
Audit log
After finishing the Subset process an audit log can be created by clicking on Audit Log.
This log shows up immediately and is also saved in a sub-folder of the project Deployment folder.
This Audit log shows information of the Source and Target database and statistics of every subsetted table.
Tab: Comments
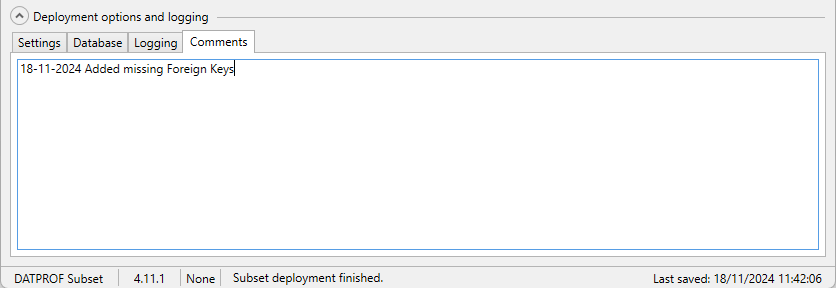
The tab Comments enables the user to add Deployment comments. This information is used whenever the user creates a report using the option Generate comments report in the menu Project.
Deployment/Starting Subset
When the user clicks the button Start… all connections are validated first before running the Subset process. If there are errors they must be fixed before the process continues.
If you encounter an error during your run and handle the error during the run (i.e. changing a faulty query) the change is not automatically applied to your template. In order to prevent future errors you will need to manually edit your template afterwards.
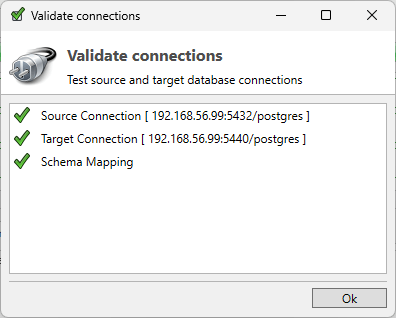
If there are no errors this screen will disappear and a dialog will show up to select a Deployment strategy.
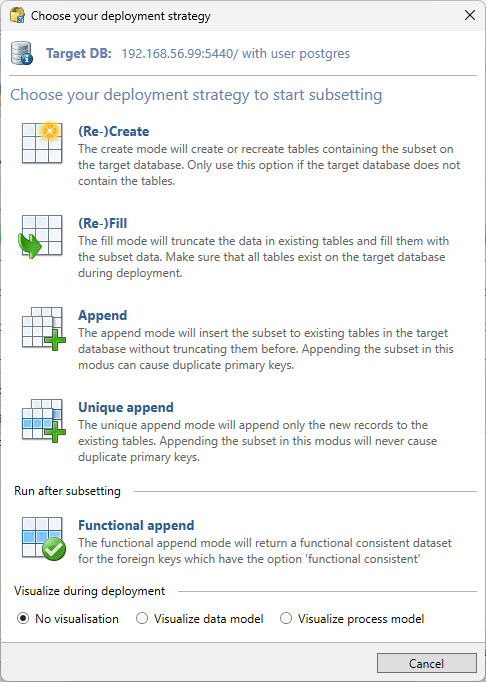
The (Re-)Create mode will (drop and) create new Tables and Foreign Keys in the Target database. No indexes, packages or other objects are created! Not all table and datatype options are supported in recreating the table on the target database. Typically the data model is created by the application.
The (Re-)Fill mode will empty the tables in the Target database and fill it with new data. The data model in the Target database should be consistent with the data model in the Source database. If not consistent the column option “not on target” might be helpful.
Using the Append mode , data from the Source database is added to the existing data in the Target database. There is no verification done to check if a Primary Key exist or not.
The Unique Append mode is similar to the Append Mode. Now a check is done to add only new and unique data, based on the primary key, to the table.
The Functional Append mode enables the user to start a Functional Iteration after the normal Subset process has finished. This only applies to the Foreign Keys which are flagged for Functional Iteration.
This function is meant for development purposes to add a Functional Consistency check on a Foreign Key and check the results without a full Subset run.
At the bottom of this dialog screen the user can choose to either view a graphical representation of the datamodel or the processmodel during deployment. If the datamodel is very large this visualization will be slow!
Options during Deployment
During Deployment three options are available.
Pause: The process will hold on temporarily. A dialog shows up and only when clicking ok the deployment continues.
Abort: The Deployment process will abort.
Errors: Only available when an error occurred.
Errors during Deployment
If an error occurs during Deployment the button Errors is enabled. Pressing this button shows a dialog screen with the errors. Every row contains both the error and a drop-down box containing three options to choose the follow-up action.
None: The Subset process stops. This is the default value.
Retry: This option will make the current process to restart at the current point. Before doing this it is possible to adjust the cause of the error. The normal way to do this is to keep the Action on None, click Cancel, adjust the code, go back to this Errors dialog, select Retry as Action and click Apply.
Skip: Selecting the action Skip will ignore the error and continue with the next process step.
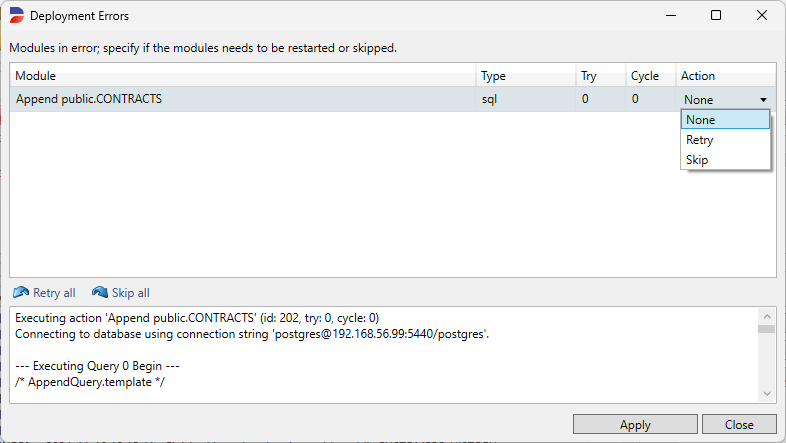
Every action must be confirmed by clicking Apply.
Runtime Deployment
To deploy your template on DATPROF Runtime, you first have to generate a Runtime application. This will generate all the needed information into a zipped Runtime application that can be uploaded in DATPROF Runtime. In Runtime you can install that generated application in multiple environments and change the parameters like source en target connections.
To generate a Runtime application, click Project → Generate for Runtime ....
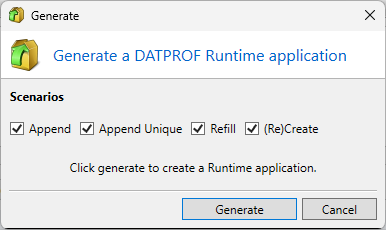
Click Generate to create a Runtime application. After the generation is completed a new explorer window is opened that will show the generated Runtime application. The Runtime manual explains how to upload and deploy generated Runtime applications.