Introduction
Concepts
Development, Testing, QA and Training databases are regularly deployed in support of the business applications. Most organizations use full copies of production databases for this purpose. These production databases can be very large, which impacts testing runtimes, disk space requirements and their attendant management and backup requirements:
- Creating a backup can be a lengthy process and is not readily available.
- Restoration of a production copy to a testing environment can often take a lot of time.
- The testing infrastructure has to be comparable to the production environment to have similar performance characteristics, which can be very expensive.
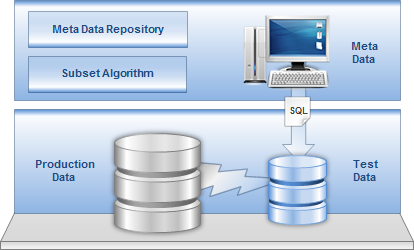
DATPROF Subset selects data from a full size production database which we describe as the “Source database”. This data goes to a copy of the database which is deployed in support of the non-production functions. In DATPROF Subset this is called the “Target database”. By applying filters when populating the Target database it will be smaller in size than the Source database. This enables faster testing, saving time and therefore money.
The main method DATPROF Subset uses is to access the data via one central table in the Source database which is called the Start table. Other table content is extracted based upon Foreign Key relations with the Start table and, subsequently, across the Relational Integrity model.
During deployment of the Subset project only a connection between Source and Target database is needed. No data passes through DATPROF Subset. This has a favourable impact on performance in that it typically keeps traffic on the network "spine" and away from End-Points (a key security consideration).
A small example.
The example below shows three tables. There are 100 Customers, 1000 Orders and 10000 Order Lines in the Source database.
Every customer has 10 orders and every order has 10 related order_lines.
Only 10 customers have a name starting with ‘A’.
Source database containing all customers, orders and order lines

If the Customers table is the Start table and we only select Customers having a name starting with an ‘A’, this will result in a Target database with 10 Customers, 100 orders and a total of 1000 order_lines.
Target database with only customer names starting with 'A' and their related orders and order lines.

The result is a Target database that is 90% smaller than (or 10% of the size of) the Source database, retaining data consistency and referential integrity.
DATPROF Subset enables the user to save these filters and functions so that they can be deployed repeatedly. This way a controlled Subset process emerges.
After subsetting, the data in the Target database can be used for testing purposes, but can also be the base for anonymization using DATPROF Privacy.
The steps to take
To create a Subset using DATPROF Subset for the first time, the following steps should be followed:
- Create a new Project and the Template.
- Setup the connections to both the Source and Target databases.
- Import the datamodel of the Source database into the Metadata of DATPROF Subset.
- Develop and configure the project.
- Deploy the Subset project