Data Masking
In the masking chapter we’ll go over the Masking tab in Privacy, and the various masking functions available to the user. In order to configure any functions in a project, meta data has to be imported after project creation.
Schema / Table overview
On the left-hand side of the Privacy interface the user can consult the metadata overview. This is a collection of tables and schemas imported into the project divided by per schema. To switch between the currently depicted schema content the user can click on the drop-down letterbox at the top of the table overview window containing the name of the currently active schema.
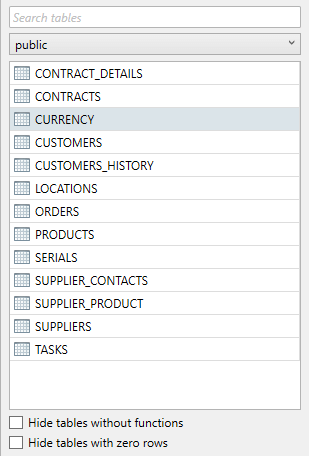
Searching tables
In order to search for tables, the user can enter a search query at the top of the schema overview. As the search result gets filtered down results that do not comply with the query will be hidden from the overview, leaving the user with only matching tables. On top of this, the drop-down box containing the name of the schema also indicates how many matches are found using the currently active search query. If the user opens this drop-down box, it will indicate the amount of matches per schema. If a matching table is located in a different schema, the result will not be shown automatically to the user.
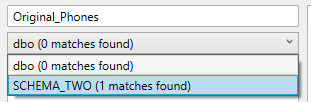
The user can supply wildcard characters in the search query as well, in order to find tables using partial matches.
Example:
Imagine we want to find all tables containing the word “supplier“. Supplying “supplier%” as our search query would make sure all tables starting with the word supplier with any characters after it are matched, such as SUPPLIER_CONTACTS, SUPPLIER_PRODUCT, and SUPPLIERS, but not DAIRY_SUPPLIERS.
Right-click context menu
The user can right-click on any table in the table overview to do one of four actions:
Count the number of rows in one or more table(s), for which an active database connection is required. The result is stored as a value next to the name of any given table.
Clear any previously generated table row counts.
Delete the table(s). This merely deletes the table from the Privacy template and does not affect the data model itself. Any existing functions and configurations on a table are simultaneously removed.
Sort the displayed tables in one of four ways: table name (ascending), table name (descending), row count (ascending), and row count (descending).
You can select multiple columns using the standard Windows <SHIFT> or <CTRL> options to select a range or selection of columns.
Additional Options
As of now there are two additional options available below the table overview:
Hiding all tables without functions.
Hiding all tables with zero rows. This option only affects tables of which the row count is known, so a row count is required beforehand.
Column overview
In the column overview on the right-hand side of the masking tab the user can access available information about all imported columns in a table. Depending on the chosen database type, slightly different notation for metadata traits can be displayed.
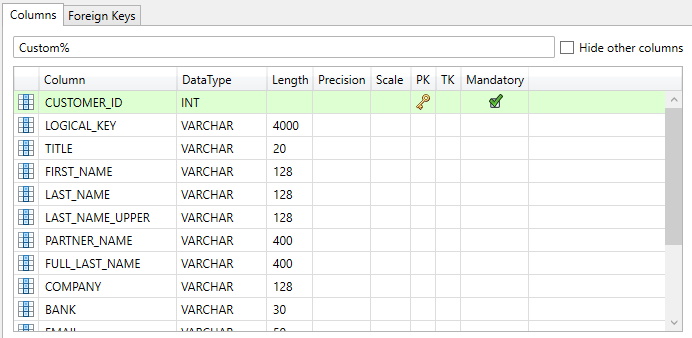
Searching Columns
Searching columns in the column overview works largely in the same manner as the searching tables, which is highlighted in the Searching tables section of this page. One key difference is that instead of hiding any results that do not match the search string, the column overview highlights any matching columns in green, unless the Hide other columns button on the right side of the search bar is ticked.
Right-click context menu
The user can right-click on any column in the table overview to do one of three actions:
Add a masking function. This option allows the user to select a valid masking function and create it on the select column(s), opening the function’s configuration menu. Certain functions can be applied to multiple columns at once, such as the Blank function.
Toggle primary key. This option indicates a column as being a primary key in Privacy. This is useful is a primary key is not correctly imported due to database configuration.
Toggle translation key. This option indicates a selected column as a translation key. This functionality is explained later in the Saving a translation table chapter of this page.
Data masking functions
The following data masking functions are available in DATPROF Privacy:
Blank
Scramble
Shuffle
First day in same month/year
Value lookup
Random Lookup
Custom Expression
Generate (containing multiple generation types)
JSON Functions
Masking functions are all data type dependant, and are automatically enabled or disabled depending on which column is selected. The Datatype and Function matrix at the end of this manual lists, per database, the functions available for the different datatypes.
Blank
This function will NULL the selected column(s). This function can’t be used on columns which are specified as NOT NULL or columns upon which a Primary Key (PK) is defined.
Examples
Original value | New Value |
|---|---|
Abcdefg | NULL |
123456 | NULL |
Scramble
This scramble function ensures that for numeric data types all characters are replaced with the number ‘1 ', and alphanumeric data types all characters are replaced by the symbol 'x' or 'X’, depending on whether the original character was capitalized or not. The length of any supplied cell is maintained.
Examples
Original value | New Value |
|---|---|
MindBox | XxxxXxx |
0612345678 | 1111111111 |
José Nemeç | Xxxé Xxxxç |
For MySQL version 5.x databases the scramble function is simplified due to limitations on database functions. All alphanumeric characters are instead replaced by “XXX”.
Characters with diacritic marks are left unchanged
Shuffle
The shuffle function ensures that all values in the selected column(s) are randomly mixed, like shuffling a deck of cards. The data distribution remains the same, which will ensure that the same values in the former situation, also obtain the same new values. A normal shuffle is a shuffle without selecting the group check-boxes.
Example of the Function Editor with a normal shuffle: Shuffle LAST_NAMES.
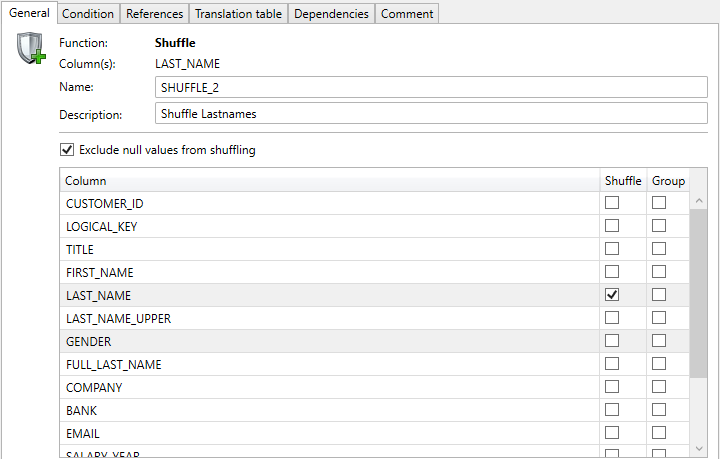
If the function is applied to more than one column at the same time, a multi column shuffle is applied. The values of the selected columns remain together and will be shuffled as a whole. In this way, for example, the gender and a first name are held together.
The option 'Exclude null values from shuffling' ensures that NULL values will not be considered for shuffling, retaining their place in their specific row(s).
The random order on a low number of records may result in original values. Consider this: the random order of 1,2,3 may well be 2,1,3, keeping "3" the original value.
Examples
Original situation | New situation | ||
|---|---|---|---|
FIRST_NAME | LAST_NAME | FIRST_NAME | LAST_NAME |
Steve | Jobs | Steve | Gates |
Bill | Gates | Bill | Jobs |
Blaise | Pascal | Blaise | Page |
Larry | Page | Larry | Pascal |
Melinda | Gates | Melinda | Jobs |
A shuffle is a random function on the unique distinct values of the set. See "Gates" in the example above. Both Melinda Gates and Bill Gates were renamed to have Jobs as their surname, because they shared the same original surname.
Group Shuffle
The Group shuffle is a variation of the shuffle. In the application you add this function as a normal function and also check the Group check-boxes.
You may select one or more columns as a group. Within this group the unique values of the selected columns are shuffled.
NULL or Empty values in the Group column are considered as a group.
By using a group shuffle fewer values are used to shuffle because only unique values within in a group are used to shuffle. For this reason the "group" column(s) should result in a reasonable number of values to shuffle.
Example of the Function Editor with a group shuffle: Shuffle FIRST_NAMES grouped by GENDER.
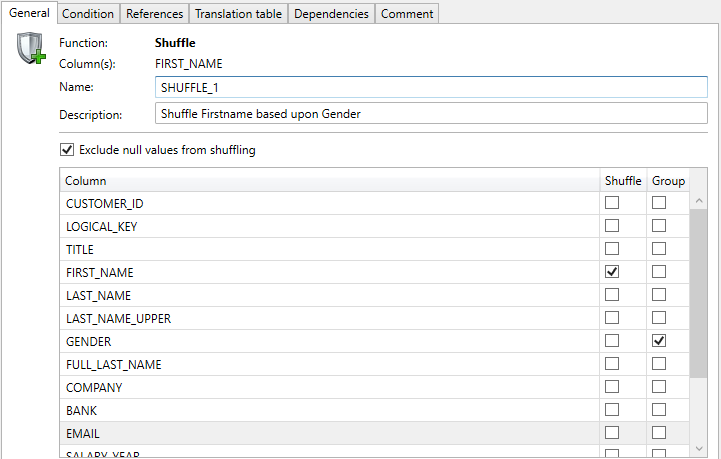
Examples
Original situation | New situation | ||
|---|---|---|---|
FIRST_NAME | GENDER | FIRST_NAME | GENDER |
Steve | M | Kelly | M |
Kelly | M | Steve | M |
Blaise | Blaise | ||
Kelly | F | Melissa | F |
Melissa | F | Kelly | F |
Kelly | M | Steve | M |
Melissa | F | Kelly | F |
Maxima | Maxima | ||
Above we see three Gender groups: M, F and Empty.
Kelly exists as Male and Female. Blaise and Maxima have no gender.
The group shuffle using FIRST_NAME as column and GENDER as Group results in shuffling three groups where the empty group, having only two records, does not change.
It’s important to make sure that the field you use to group your result is:
Complete. Having NULL values in your dataset can result in unmasked fields
Consistent. If you group by gender like in the above example and have a small percentage of fields with for instance “V” instead of “F”, you can introduce fields that are shuffled in a tiny group, which can cause issues.
Fixed day in same month/year
This feature can be used for date fields only. Here the user has the ability to change the existing date to a fixed day in the same month. Or to a fixed day in the first month of the same year. With this change, in most cases the new values remain functionally viable.
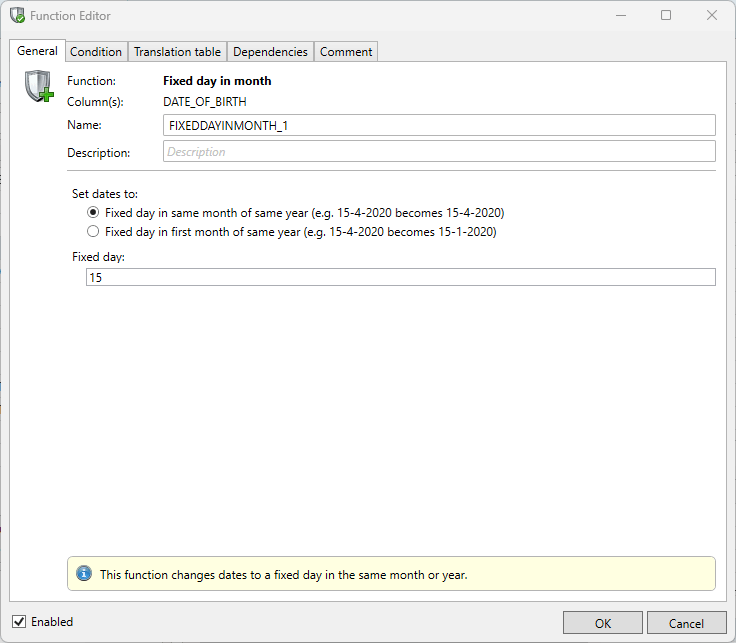
Examples
Fixed day: 13 | Original value | New value |
|---|---|---|
Fixed day in same month | 23-04-2018 | 13-04-2018 |
Fixed day in first month of same year | 16-09-2020 | 13-01-2020 |
Custom Expression
Note: This feature can use AI to help with your custom expressions. Please review our AI Disclaimer
The ‘Custom Expression’ is a generic function where any and all database platform functions can be used to manipulate the data in the selected column.
Examples
Function | Original value | New Value |
|---|---|---|
substr(<column>,1,3) | Datprof | Dat |
'company' | Datprof | company |
translate(<column>,'aeiouyAEIOUY','************') | Datprof | D*tpr*f |
<column> / 4 | 10 | 2.5 |
<column> - 2 | 21-05-2015 | 19-05-2015 |
regexp_replace('<column>','([[:digit:]^]{1})([[:digit:]^]{1})([[:digit:]^]{1})','\3\1\2') | 789 | 978 |
To verify the syntax of the expression it can be tested using the Test button which will send the defined expression to the database for verification. The verification shows if the expression is valid or not with a message next to the Test button, per the panel below, if invalid. A valid expression will return 'Query validated'
Testing an expression requires an active database connection.
Starting with Privacy version 4.21.0, you can now use AI to assist in creating custom expressions. Always review and validate the AI‑generated output before using it.
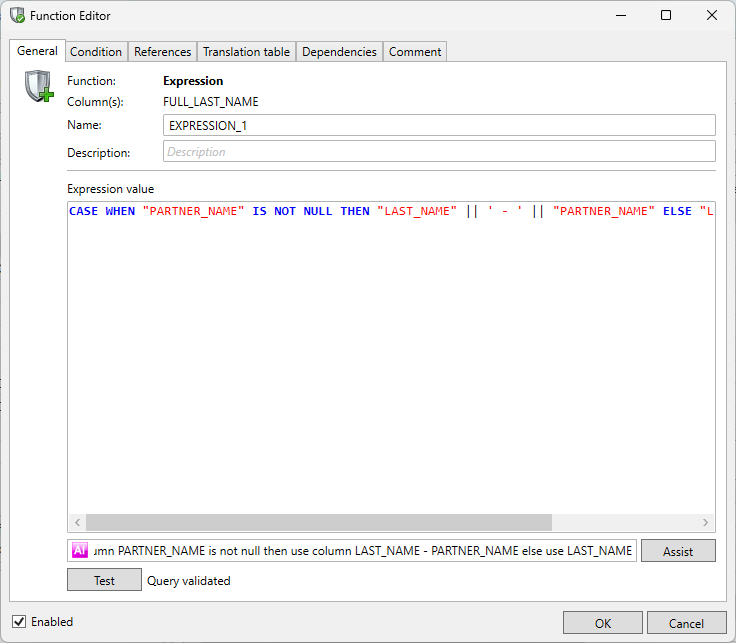
Value Lookup
With this function the replacement value will be obtained from a lookup table or translation table. This translation table may well be the result of a previously executed Privacy function where, for instance, consistent masking was implemented using the translation table methodology.
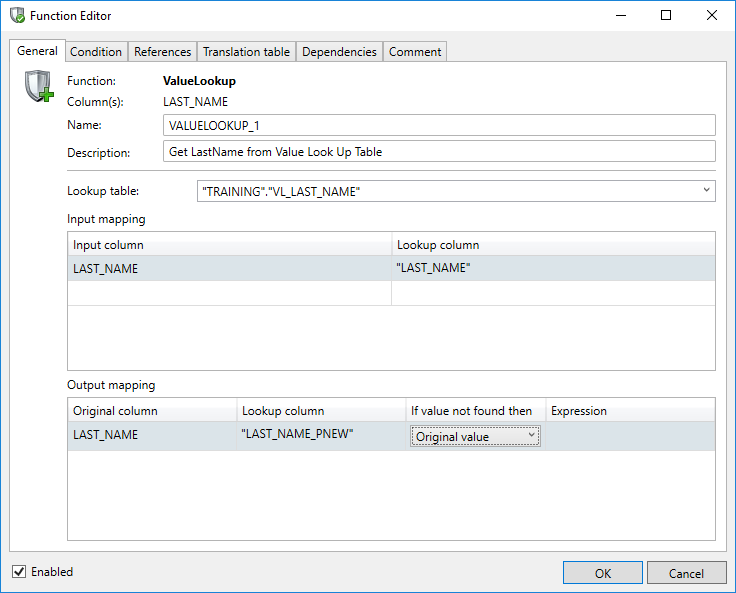
The field Name can be used to enter a meaningful name.
The field Description allows you to enter a description of the rule which will be displayed in the comments report.
The field Lookup Table is a combo-box which allows the user to either select a table from a list or specify a table name manually. This lookup table contains both the columns to search for and the columns containing data to replace the original values with.
If another Privacy function uses the Translation Table feature the result is saved as a Translation table and will be shown in the drop-down list.
If the Lookup table is built outside a Privacy function it will not be present in the list and must be manually entered.
A manually entered Lookup table should have a fully qualified name including the Schema name and/or Database name. i.e: [db1].dbo].[mytable] or "SCHEMAOWNER1"."VL_NAMES" or "schemaowner2"."vl_names"
Using a view as a lookup table
A manually entered lookup table may well be a view created by you or your DBA.
Depending on the complexity of the view and size of the dataset you may encounter a significant performance penalty.
Consider creating a temporary table instead of using a view. Benchmarks show a performance boost up to 95% by using a table instead of a view.
The search criteria can be entered under Input mapping.
The Input column is a drop-down list where the search column can be selected.
The Lookup column is a combo-box where, if the Lookup table is generated by a Privacy function, the fields to search for are listed for selection. With other tables the field name should be entered manually.
You can enter SQL functions here to filter the provided field.
I.E. if you have a composite key (8 digits for customer number + 3 digits for region code for instance), and you want to search based on the first 8 digits, you could do the following in an Oracle environment:
SUBSTR(COMPOSITE_KEY,1,8)
This can turn a number such as 12345678900 into 123456789.
Under Output mapping it is possible to select the columns to replace the original values with replacement data from the Lookup table.
The Original column is a drop-down list where the column name must be selected with the data to be replaced.
The Lookup column is a combo-box where, if the Lookup table is generated by a Privacy function, the column in the Lookup table can be selected from a list to replace the Original data with. With other tables the column name should be entered manually.
The If value not found then feature provides options to take should the Original column value not exist in the Lookup table. Options include retaining the original value, NULL'ing the item, specifying a Custom Expression or Scrambling (redacting) the existing value.
Random Lookup
Using this function, which is a variation of the Value Lookup, a new value will be randomly obtained from a 'Lookup' or 'Translation' table.
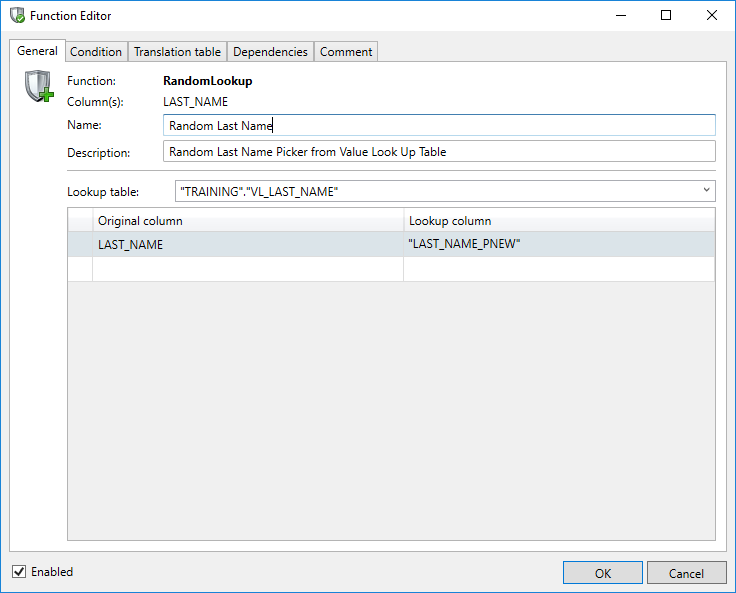
When using a Random Lookup an equivalent value in two or more tables will not be consistently replaced.
As with the Value Lookup a Lookup table and a Lookup column can be chosen from a combo-box list or be entered manually.
A manually entered Lookup table should have a fully qualified name including the Schema name and/or Database name. i.e: [db1].dbo].[mytable] or "SCHEMAOWNER1"."VL_NAMES" or "schemaowner2"."vl_names"
JSON Functions
DATPROF Privacy can detect JSON and JSONB column structures and apply masking or generation functions to individual fields within those documents using JSONPath expressions. This section covers how to configure JSON masking rules, write correct JSONPath selectors, and understand the behaviour of attribute ordering.
JSON/JSONB masking is currently available for PostgreSQL only. Support for additional databases is planned for a future release.
Important note on attribute ordering:
When processing JSON, the order of attributes in each JSON object cannot be guaranteed. Attributes are written out alphabetically. While this does not affect how data reading software interprets the file, it may appear unusual when inspecting the file manually.
JSONPath
To mask fields in your database, you’ll need to define them using JSONPath. JSONPath provides a structured way to locate and reference specific fields within your data. This flexibility allows you to mask fields at various levels of your data hierarchy.
The JSONPath expression always starts with $ (the document root) and uses dot notation to navigate to the target field.
In the example below, you can see a demo database structure. To mask the field first_name, you can use its full JSONPath: $.first_name.
For more complex structures, such as arrays, you’ll need to use the JSONPath to navigate to the nested fields. For instance, consider an array named customerhistories that contains multiple fields. To mask the first_name field within this array, the JSONPath would be $.customerhistories.first_name. This ensures that the masking process targets the correct field within the array.
Examples:
JSONPath | Targets |
$.first_name | The first_name value at the root of the JSON object |
$.last_name | The last_name value at the root of the JSON object |
The email value at the root of the JSON object | |
$.address.street | The street field inside the nested address object |
$.address.city | The city field inside the nested address object |
$.address.country | The country code inside the nested address object |
Value lookup
Value Lookup replaces the content of a JSON field with a value drawn from a reference (lookup) table. The replacement is deterministic: the same source value always maps to the same masked value across multiple runs, preserving referential integrity.
We’ll use this sample data to demonstrate the Value lookup function for JSON:
{"id": 1, "age": 21, "tags": ["admin", "premium"], "location": "New York", "last_name": "Smith", "first_name": "Elias", "preferences": {"theme": "dark", "language": "en", "notifications": true}}
{"id": 2, "age": 22, "tags": ["user"], "location": "London", "last_name": "Jones", "first_name": "Tarah", "preferences": {"theme": "light", "language": "es", "notifications": true}}
{"id": 3, "age": 23, "tags": ["user"], "location": "Madrid", "last_name": "Diaz", "first_name": "Erica", "preferences": {"theme": "dark", "language": "fr", "notifications": false}}
{"id": 4, "age": 24, "tags": ["user"], "location": "Berlin", "last_name": "Brown", "first_name": "Tad", "preferences": {"theme": "light", "language": "de", "notifications": true}}
{"id": 5, "age": 25, "tags": ["user", "beta-tester"], "location": "Paris", "last_name": "Wilson", "first_name": "Francis", "preferences": {"theme": "dark", "language": "ja", "notifications": true}}
{"id": 6, "age": 26, "tags": ["user"], "location": "Tokyo", "last_name": "Taylor", "first_name": "Maryalice", "preferences": {"theme": "light", "language": "en", "notifications": false}}
{"id": 7, "age": 27, "tags": ["user"], "location": "Sydney", "last_name": "Anderson", "first_name": "Aron", "preferences": {"theme": "dark", "language": "es", "notifications": true}}
{"id": 8, "age": 28, "tags": ["user"], "location": "Toronto", "last_name": "Thomas", "first_name": "Delila", "preferences": {"theme": "light", "language": "fr", "notifications": true}}
{"id": 9, "age": 29, "tags": ["user"], "location": "Dubai", "last_name": "Jackson", "first_name": "Andy", "preferences": {"theme": "dark", "language": "de", "notifications": false}}
{"id": 10, "age": 30, "tags": ["user", "beta-tester"], "location": "Rome", "last_name": "White", "first_name": "Beatrice", "preferences": {"theme": "light", "language": "ja", "notifications": true}}The goal is to mask the first_name with a lookup table “lookup” we’ve created already. This lookup table has the following data:
1 Alice
2 Bob
3 Carla
4 David
5 Eva
6 Frank
7 Grace
8 Hank
9 Iris
10 JakeTo configure the Value lookup function, you must specify the input mapping and output mapping:
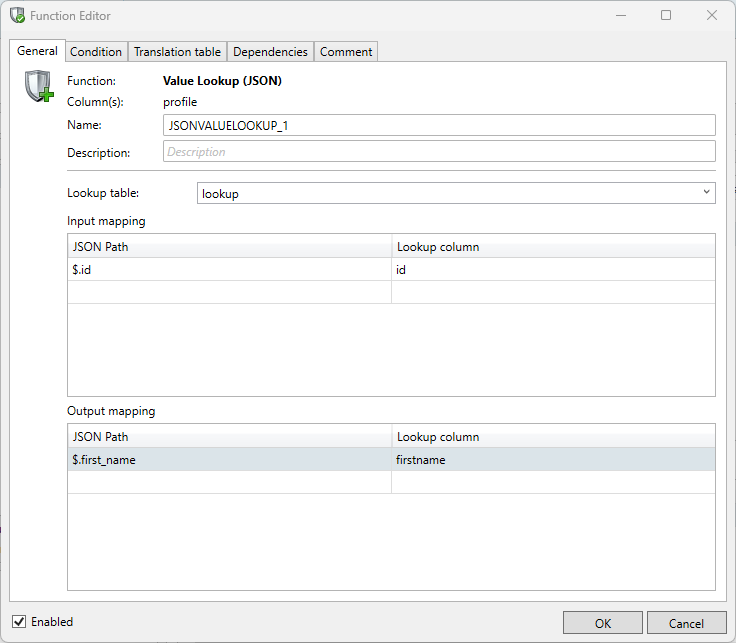
Both input and output mapping require a JSON Path and a Lookup column.
Input mapping
What | Explanation | Example |
|---|---|---|
JSON Path | requires the JSON path of the target field you want to match with the Lookup column | $.id |
Lookup column | requires the lookup column of which you want to match with the JSON value | id |
What | Explanation | Example |
|---|---|---|
JSON Path | The JSON value you’d like to replace | $.first_name |
Lookup column | The column you’d like to use as values | firstname |
Result:
{"id": 1, "age": 21, "tags": ["admin", "premium"], "location": "New York", "last_name": "Smith", "first_name": "Alice", "preferences": {"theme": "dark", "language": "en", "notifications": true}}
{"id": 2, "age": 22, "tags": ["user"], "location": "London", "last_name": "Jones", "first_name": "Bob", "preferences": {"theme": "light", "language": "es", "notifications": true}}
{"id": 3, "age": 23, "tags": ["user"], "location": "Madrid", "last_name": "Diaz", "first_name": "Carla", "preferences": {"theme": "dark", "language": "fr", "notifications": false}}
{"id": 4, "age": 24, "tags": ["user"], "location": "Berlin", "last_name": "Brown", "first_name": "David", "preferences": {"theme": "light", "language": "de", "notifications": true}}
{"id": 5, "age": 25, "tags": ["user", "beta-tester"], "location": "Paris", "last_name": "Wilson", "first_name": "Eva", "preferences": {"theme": "dark", "language": "ja", "notifications": true}}
{"id": 6, "age": 26, "tags": ["user"], "location": "Tokyo", "last_name": "Taylor", "first_name": "Frank", "preferences": {"theme": "light", "language": "en", "notifications": false}}
{"id": 7, "age": 27, "tags": ["user"], "location": "Sydney", "last_name": "Anderson", "first_name": "Grace", "preferences": {"theme": "dark", "language": "es", "notifications": true}}
{"id": 8, "age": 28, "tags": ["user"], "location": "Toronto", "last_name": "Thomas", "first_name": "Hank", "preferences": {"theme": "light", "language": "fr", "notifications": true}}
{"id": 9, "age": 29, "tags": ["user"], "location": "Dubai", "last_name": "Jackson", "first_name": "Iris", "preferences": {"theme": "dark", "language": "de", "notifications": false}}
{"id": 10, "age": 30, "tags": ["user", "beta-tester"], "location": "Rome", "last_name": "White", "first_name": "Jake", "preferences": {"theme": "light", "language": "ja", "notifications": true}}Generate
The generate function creates brand-new synthetic values for a JSON field. Unlike the Value lookup function, it does not require a lookup table but makes use of the existing generators already built into Privacy.
We’ll again use this sample data and will mask the first_name inside the “profile” column.
{"id": 1, "age": 21, "tags": ["admin", "premium"], "location": "New York", "last_name": "Smith", "first_name": "Elias", "preferences": {"theme": "dark", "language": "en", "notifications": true}}
{"id": 2, "age": 22, "tags": ["user"], "location": "London", "last_name": "Jones", "first_name": "Tarah", "preferences": {"theme": "light", "language": "es", "notifications": true}}
{"id": 3, "age": 23, "tags": ["user"], "location": "Madrid", "last_name": "Diaz", "first_name": "Erica", "preferences": {"theme": "dark", "language": "fr", "notifications": false}}
{"id": 4, "age": 24, "tags": ["user"], "location": "Berlin", "last_name": "Brown", "first_name": "Tad", "preferences": {"theme": "light", "language": "de", "notifications": true}}
{"id": 5, "age": 25, "tags": ["user", "beta-tester"], "location": "Paris", "last_name": "Wilson", "first_name": "Francis", "preferences": {"theme": "dark", "language": "ja", "notifications": true}}
{"id": 6, "age": 26, "tags": ["user"], "location": "Tokyo", "last_name": "Taylor", "first_name": "Maryalice", "preferences": {"theme": "light", "language": "en", "notifications": false}}
{"id": 7, "age": 27, "tags": ["user"], "location": "Sydney", "last_name": "Anderson", "first_name": "Aron", "preferences": {"theme": "dark", "language": "es", "notifications": true}}
{"id": 8, "age": 28, "tags": ["user"], "location": "Toronto", "last_name": "Thomas", "first_name": "Delila", "preferences": {"theme": "light", "language": "fr", "notifications": true}}
{"id": 9, "age": 29, "tags": ["user"], "location": "Dubai", "last_name": "Jackson", "first_name": "Andy", "preferences": {"theme": "dark", "language": "de", "notifications": false}}
{"id": 10, "age": 30, "tags": ["user", "beta-tester"], "location": "Rome", "last_name": "White", "first_name": "Beatrice", "preferences": {"theme": "light", "language": "ja", "notifications": true}}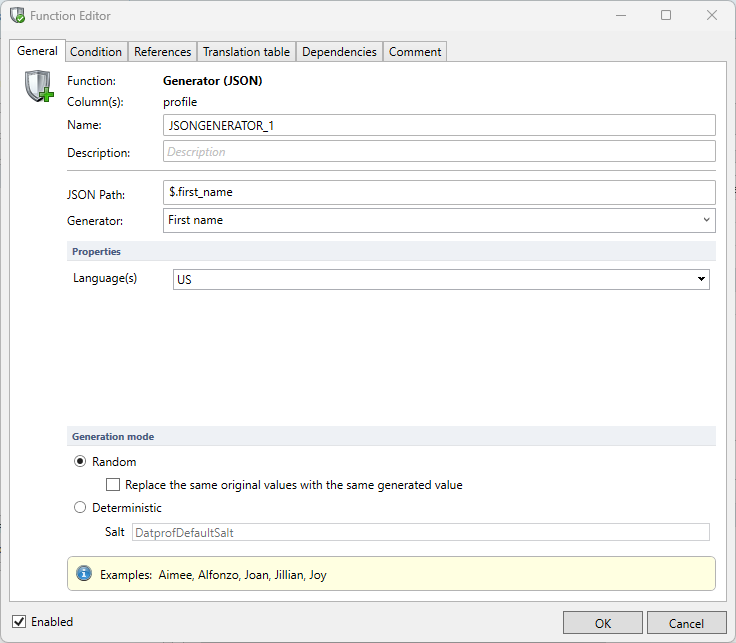
Result:
{"id": 1, "age": 21, "tags": ["admin", "premium"], "location": "New York", "last_name": "Smith", "first_name": "Rosana", "preferences": {"theme": "dark", "language": "en", "notifications": true}}
{"id": 2, "age": 22, "tags": ["user"], "location": "London", "last_name": "Jones", "first_name": "Colby", "preferences": {"theme": "light", "language": "es", "notifications": true}}
{"id": 3, "age": 23, "tags": ["user"], "location": "Madrid", "last_name": "Diaz", "first_name": "Joey", "preferences": {"theme": "dark", "language": "fr", "notifications": false}}
{"id": 4, "age": 24, "tags": ["user"], "location": "Berlin", "last_name": "Brown", "first_name": "Marielle", "preferences": {"theme": "light", "language": "de", "notifications": true}}
{"id": 5, "age": 25, "tags": ["user", "beta-tester"], "location": "Paris", "last_name": "Wilson", "first_name": "Gabrielle", "preferences": {"theme": "dark", "language": "ja", "notifications": true}}
{"id": 6, "age": 26, "tags": ["user"], "location": "Tokyo", "last_name": "Taylor", "first_name": "Melia", "preferences": {"theme": "light", "language": "en", "notifications": false}}
{"id": 7, "age": 27, "tags": ["user"], "location": "Sydney", "last_name": "Anderson", "first_name": "Roxie", "preferences": {"theme": "dark", "language": "es", "notifications": true}}
{"id": 8, "age": 28, "tags": ["user"], "location": "Toronto", "last_name": "Thomas", "first_name": "Francis", "preferences": {"theme": "light", "language": "fr", "notifications": true}}
{"id": 9, "age": 29, "tags": ["user"], "location": "Dubai", "last_name": "Jackson", "first_name": "Raleigh", "preferences": {"theme": "dark", "language": "de", "notifications": false}}
{"id": 10, "age": 30, "tags": ["user", "beta-tester"], "location": "Rome", "last_name": "White", "first_name": "Patricia", "preferences": {"theme": "light", "language": "ja", "notifications": true}}Generation functions
Generation functions are handled in the Generation chapter of the documentation, as they function identically.
Adding data masking functions
To configure a new masking function, the user must first select the column (or multiple columns) upon which the function is to be executed. Functions can be added with either the Add Function button or a right click on the selected the column(s).
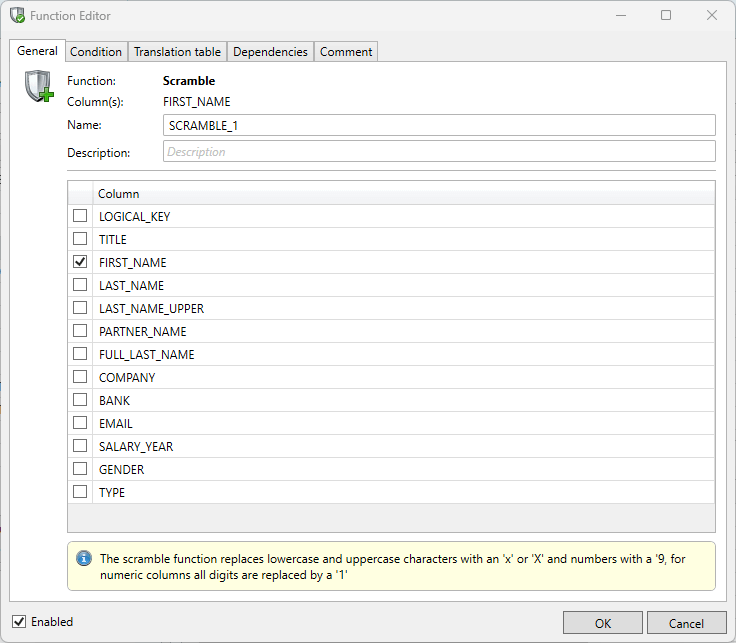
The subsequent dialogue box (called the Function Editor) allows the user to select various options for the function. These options are explained in the following sections. If the OK button is clicked, the function is added to the selected column(s). By unchecking the Enabled checkbox, this function will be skipped.
Conditional masking
The user has the option to specify a condition which selects the rows against which the function will, or will not, be executed. A condition is defined in the Condition tab in the Function Editor.
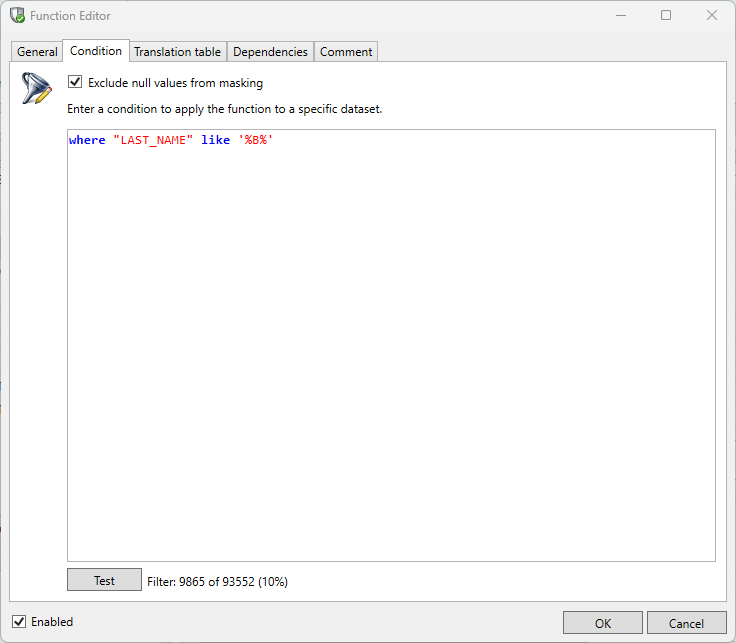
The condition can be specified by defining a 'where clause' as in an SQL query. If the "Exclude null values from masking" option is selected this will be joined with your where clause. If a where clause is not specified but the "Exclude null values from masking" is selected then only column content which is NOT NULL will be masked.
The Test button can be used to determine whether the defined condition is valid and what the result (qualified rows) of the condition will be.
Microsoft SQL Server:
To refer to the current table you can use the "table name as alias" concept. This is required whenever the “where clause” lists two identical column names. An example of a operation on table “Table2” with identical field name “name” is:
where exists (select 1 from [Table1] a where a.name = [Table2].name)
In this example "a" is the alias for [Table1].
Saving a translation table
You can choose to store the result of the data masking function in a translation table. This is particularly useful in implementing consistent data masking between tables. Translation tables store the old and the new value for each column value in the table.
You can also use a ValueLookup function against a Translation table when masking other tables or applications, effecting consistent masking across the Estate.
Saving a translation table is configured in the Translation table tab in the Function Editor. This dialog allows the user to indicate that the translation table must be created or used in subsequent runs if it already exists. The user must specify the database and schema in which the translation table is to be saved as well as a name for it.
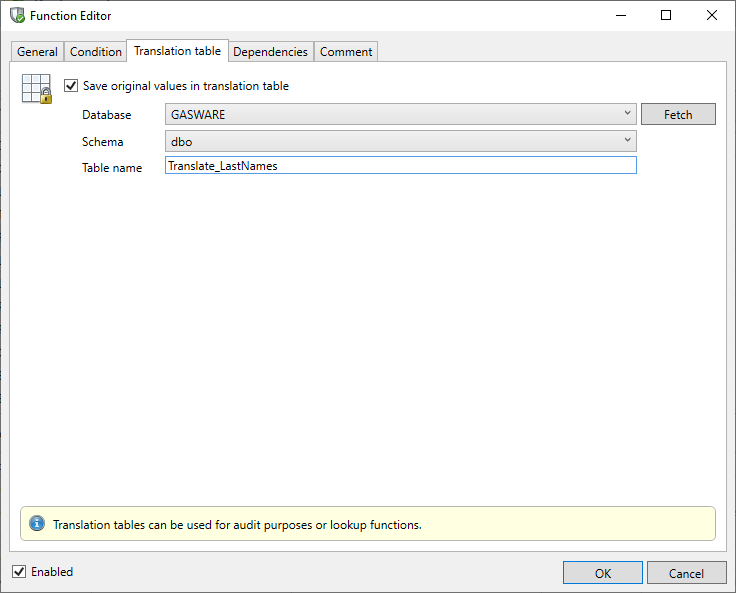
The specified translation table will be listed as a selectable table in the definition of the ValueLookup Function.
Using Translation Tables
Because translation tables contain before and after images they can present a security vulnerability in that they can be used to reverse engineer the masking process. They are not truncated or dropped by default.
Care must be taken in securing these tables from unwanted access or a post-run script executed to drop them after the masking run completes.
Best Practice: Create any used translation tables is another database which is protected by restricted/authorized access.
Dependencies
In certain cases it may be necessary to influence the sequence in which the configured functions are executed. This sequence can be specified in the Dependency Editor. The Dependency Editor can be opened using the Dependencies tab in the Function Editor. Choose the Edit button to invoke the dialogue:
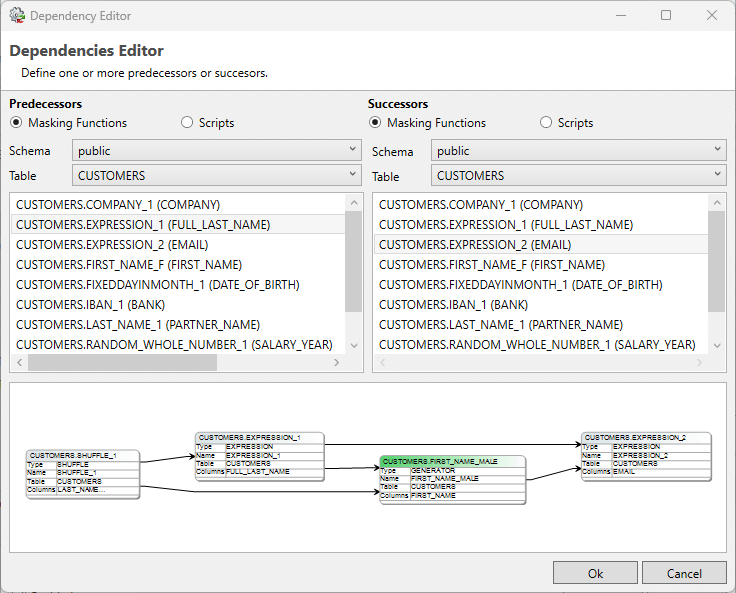
With the Dependency Editor the predecessors and successors for a function can be specified. By specifying predecessors, functions or scripts can be selected to run before the function in focus. By specifying successors, functions or scripts can be selected that should run after the selected function. Predecessors and Successors are invoked by simply clicking on the function listed in either aspect.
Sample Use Case
You have a ValueLookup function which is based upon a Translation table created in another function so the ValueLookup must run after the Translation table has been populated. A dependency will enforce this.
References
When using the Shuffle, ValueLookup and Custom Expression functions the Function Editor shows an additional References tab. It shows all the available Foreign Keys for the current field. By checking the checkbox “Update referencing foreign keys” all instances of the updated field in the database are consistently modified by following the relationships.
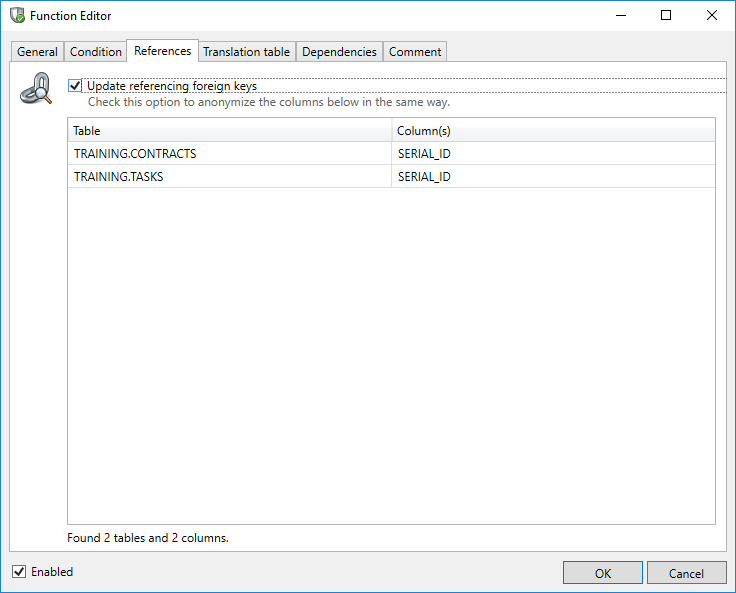
This function is extremely powerful with complex and large data models.
It is not necessary to specify a Translation Table when using this function. The Translation Table may still be required for other functions and programs.
Foreign keys
The Foreign Keys tab shows the current Foreign Keys as gathered by the Import and Synch Metadata options. Sometimes, however, data relationships are implied at the application level and not imposed at the database level. When masking (or sub-setting) a database it's often useful to have these relationships noted and, potentially, acted upon. The Foreign Keys context allows you to create, edit or delete what is, effectively, a Virtual Foreign Key which expresses the application implied relationships.
As well as listing the name of the table and the related columns the source of the Foreign Key is also displayed. There are four possibilities:
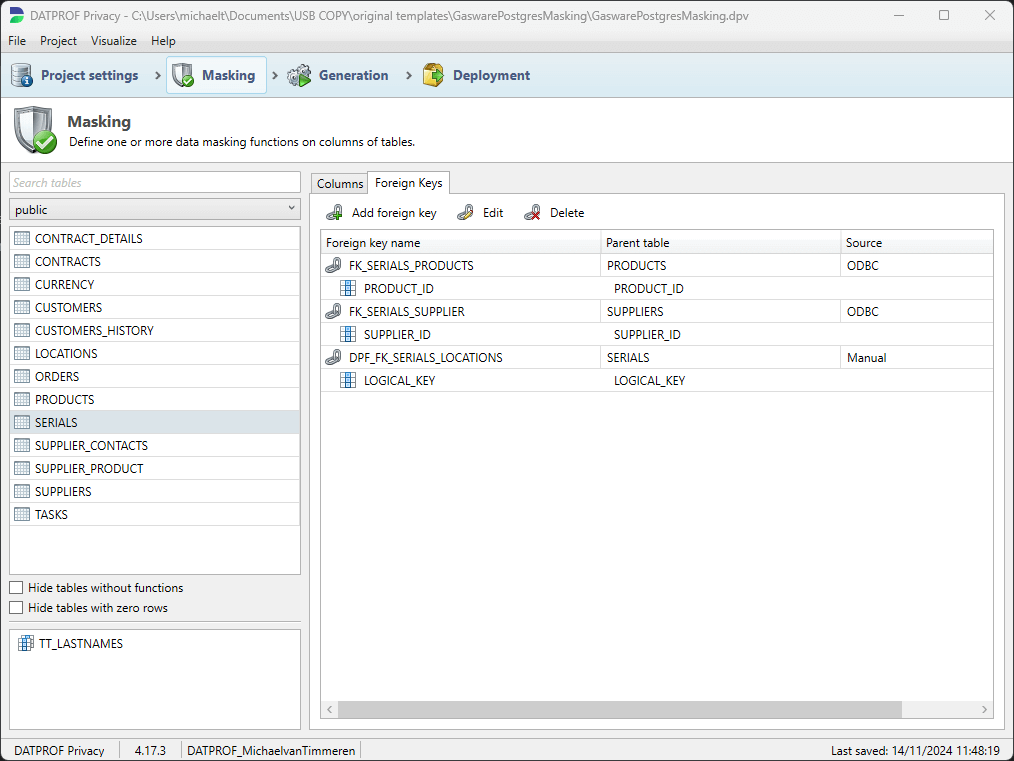
ODBC: The Foreign Key is imported from an ODBC connection.
DME: The Foreign Key is imported using a DME file.
Manual: The Foreign Key is manually created in DATPROF Privacy.
Unknown: The Foreign Key shows no indication of how it has been imported. This is likely the case with Foreign Keys created in an earlier version of DATPROF Privacy.
The distinction in the source of the Foreign Key is important to the synchronization process.
By clicking on ‘Add foreign key’ the Constraint Editor will be opened and a new virtual Foreign key can be defined.
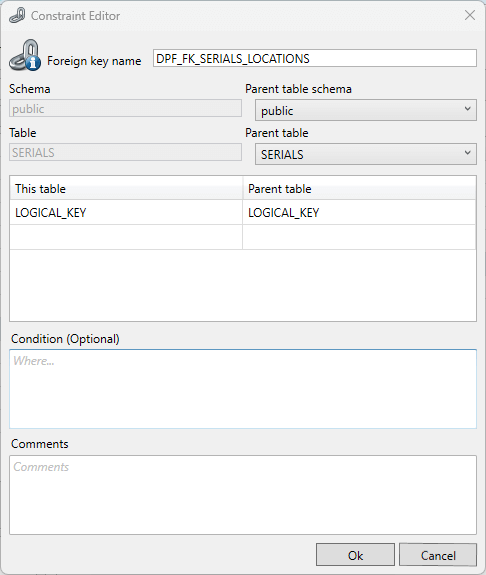
Here, a parent schema and table can be selected. A new Foreign Key can be defined by selecting the current and related columns and by selecting the parent table. When saving a new Foreign Key it will be flagged as “manually" added.
About adding a virtual Foreign Key
Adding a Foreign Key does NOT create a constraint in the database. It is exclusively used as a reference within Privacy.
The Foreign Key Condition option is currently ignored by Privacy.
A manually added Foreign Key has an impact on the synchronization wizard. The wizard considers the database as the primary source of truth, so any manually added Foreign Keys will be flagged to be removed from the metadata during a synchronize step. Therefore, it’s wise to distinguish any virtual Foreign Keys from existing Foreign Keys in the database. This way, you can avoid losing your virtual Foreign Keys.
Advanced settings
Oracle
SplitLimit
You can specify a Split Limit for every table. Selecting the tab Advanced settings for a table shows you this screen.
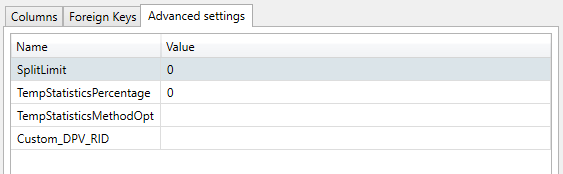
Specifying the SplitLimit has an effect on the final insert back into the table in focus. SplitLimit is synonymous with "Commit Interval" in that it groups and commits the transactions into blocks of rows specified by the SplitLimit. This will reduce the space required in the Oracle Temporary tablespace but does not apply to the DATPROF temporary tables which are created without logging.
The default value for SplitLimit = 0. All data is inserted and committed in one transaction.
Specifying the SplitLimit will impact performance.
The value used as SplitLimit is determined by your system resources, the row-count of your table and the size of the row.
TempStatisticsPercentage
By specifying a percentage > 0 Oracle statistics will be gathered prior to the merge of the masked data into the resulting table. This percentage is used as the "estimate_percent" in the Oracle query.
With large datasets this method gives a significant performance boost. For smaller datasets the time spent in gathering the statistics might exceed the time spent to merge the data, outweighing the benefits.
This setting defaults to 0, implying that no statistics will be gathered.
TempStatisticsMethodOpt
The value is used for the "method_opt" parameter of the DBMS_STATS.GATHER_TABLE_STATS procedure. When left blank (default) the parameter will be set to "FOR COLUMNS DPV_RID SIZE AUTO". Any other value will be passed as-is to the "method_opt" parameter.
For example, to gather statistics for all columns TempStatisticsMethodOpt could be set to "FOR ALL COLUMNS SIZE AUTO".
Custom_DPV_RID
The first step in masking a table is to copy the table to a temporary “Snapshot table” where a DPV_RID column is added to the table. This column will hold a Unique numeric key value.
The parameter Custom_DPV_RID allows you to specify the method to fill this column. By default this setting is empty and the following expressions are used:
For Oracle 12 this column is filled with the outcome of
rownum.
For all other Oracle versions this column is filled with the outcome of:
ROW_NUMBER() OVER (order by 1).
The reason the parameters differ is to optimize performance.
On certain occasions faster solutions are available. You could use your own expression or you might specify an existing Primary key or a sequence. This is where the setting Custom_DPV_RID can be used.
An expression returning a numeric value is required, for example a sequence: dpv_rid_sequence.nextval.
Note: Normally you do not need to fill this setting.
DB2 LUW
SplitLimit
Specifying the SplitLimit has an effect on the final insert back into the table in focus. SplitLimit is synonymous with "Commit Interval" in that it groups and commits the transactions into blocks of rows specified by the SplitLimit, thus preventing issues with the temporary tablespace.
In LUW the SplitLimit applies to both the temporary tables and the final insert into the original table.
TempStatisticsPercentage
By specifying a percentage > 0 DB2 statistics will be gathered prior to the merge of the masked data into the resulting table. This percentage is used as the percentage of the table rows using the TABLESAMPLE BERNOULLI method. With large datasets this method gives a significant performance boost. (See the IBM DB2 LUW documentation about this). This setting defaults to 0 and may be between 0 and 100. You can also use a precision of up to 2 decimal places. (ie: 0.05).
TempTablesTableSpace
When creating temporary tables the default tablespace is used. When specifying a value for this setting that tablespace will be used when temporary tables are created during the execution of the privacy function on the target table.
TempTableIndexesTableSpace
When creating temporary tables the default tablespace is used for indexes on a temporary table. When specifying a value for this setting that tablespace will be used for indexes on these temporary tables.
Databricks
Specifying JDBC properties allows fine-tuning of the connection behavior between DATPROF Runtime and a Databricks SQL Warehouse or cluster. These parameters control authentication, transport mode, encryption, and performance aspects of data transfer.
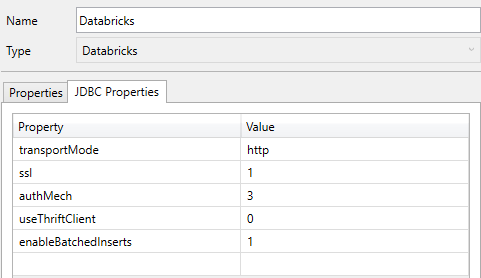
transportMode
Defines the communication protocol used by the JDBC connection. When set to HTTP, the driver communicates with Databricks using an HTTP-based Thrift transport, which is required for Databricks SQL endpoints.
Using binary mode is only applicable to on-premises Spark or Hive environments.
SSL
Enables or disables SSL encryption for the connection.
Setting ssl=1 ensures that all data transmitted between the client and Databricks is encrypted.
This setting should always remain enabled to meet Databricks’ security requirements.
authMech
Determines the authentication mechanism used for the connection.
Default is set to 3, the driver uses token-based authentication, which is required for connecting with a Databricks personal access token.
Other mechanisms include:
0: No authentication
1: Kerberos
2: Username/Password
3: Token
useThriftClient
Controls whether the JDBC driver uses the Thrift binary client.
Setting useThriftClient=0 disables the binary Thrift client, ensuring that HTTP transport is used for Databricks connections.
This value must be 0 when connecting to a Databricks SQL Warehouse.
enableBatchedInserts
When enabled (1), multiple insert statements are grouped and executed as a single batch operation.
This significantly reduces network overhead and can improve performance during large data insert operations.
Setting this property to 0 disables batching, executing each insert individually.
While this may reduce performance, it ensures more predictable behavior in certain scenarios, for example, when debugging insert errors, when strict row ordering is required, or when the target system or driver does not fully support batch operations.
In most cases, batching should remain enabled to maximize data load efficiency.
Execution of PowerShell scripts
The OS Call scripts that can be created in DATPROF Privacy are either executed as "cmd /c myscript" on Windows systems or as "/bin/sh -c myscript" on Linux systems. To execute a PowerShell script it must be saved in a separate file which can then be used from the OS Call script:
For Windows systems:
Powershell.exe -executionpolicy bypass -File "C:/path/to/mypowershellscript.ps1"Note that PowerShell's execution policy on a Windows system defaults to “Restricted” and this prevents PowerShell scripts from running. By using the “bypass” policy the script can be executed. In this cmd script a PowerShell script can be called in the following way:
Powershell.exe -executionpolicy bypass -File "C:/path/to/mypowershellscript.ps1"For Linux systems:
pwsh "/path/to/mypowershellscript.ps1"