Generation
Sometimes you cannot use existing data and you have to generate new data. The generation module now supports generating new rows inside existing tables.
The Generation section allows the user to create and configure different generations sets that generate new data. A generation set is a specific set of tables that can be configured to generate data that covers specific test data requirements. For example; 10 female customers between the age range 45 - 65, with specific contracts on specific products.
When executed, each generation set will generate its rows into a temporary table. After all temporary tables of the generators sets are filled, the data will be inserted into the original table.
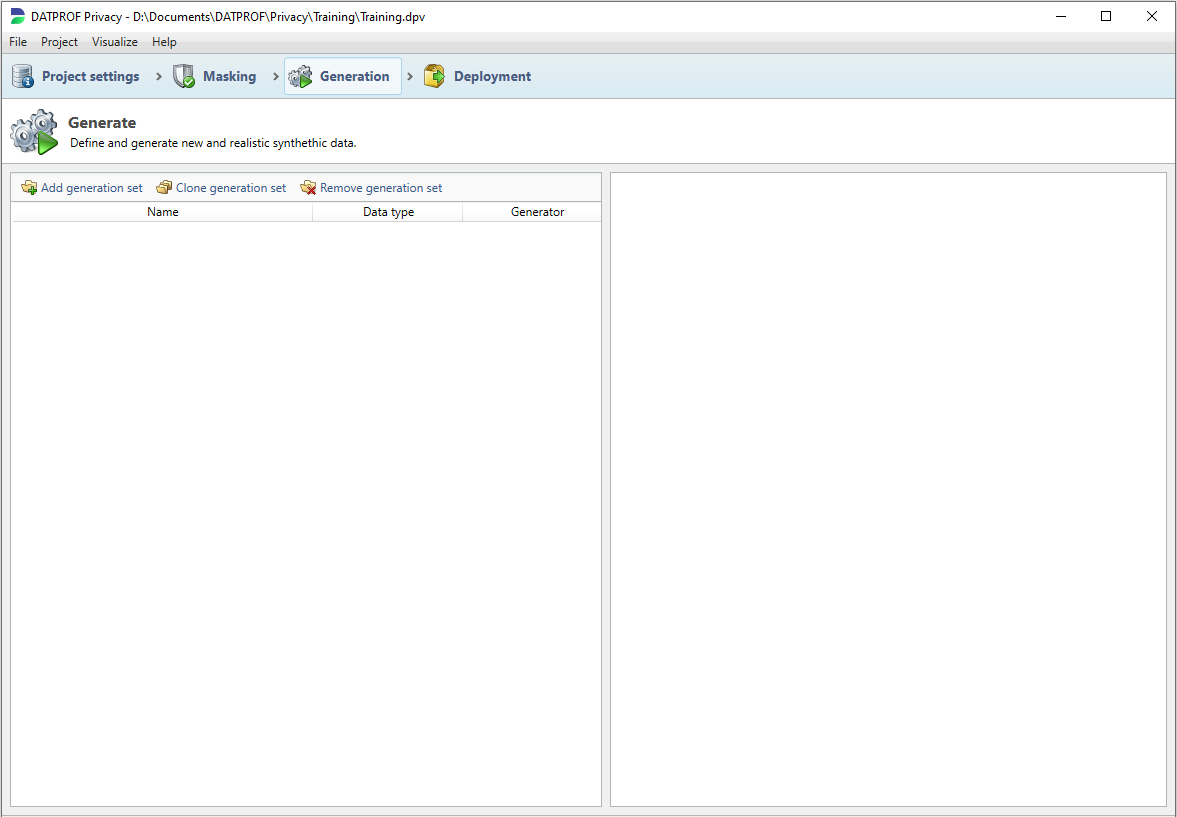
To add a new generation set, click the Add generaton set button in the toolbar. This will create an empty generation set. You can change the name and add a functional description.
After adding a generation set, you can specify which tables you want to configure. You can expand the tree view to see which tables are part of the generation set.
Table settings
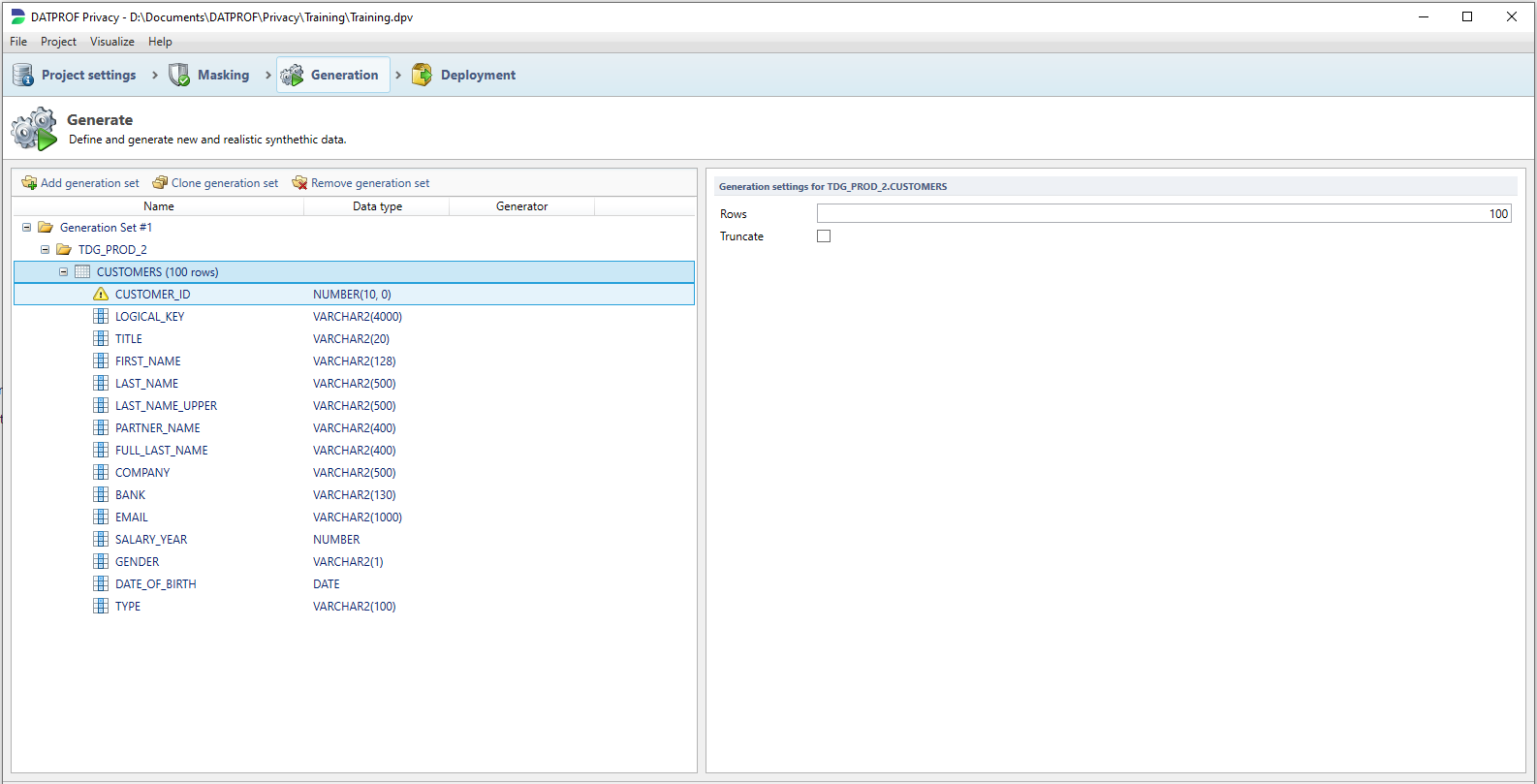
To specify how many rows you want to generate, select the specific table and change the Rows value. By default there will be 100 rows generated. You can also specify if the table should be truncated. Please note that when you generate data for the same table in different generation sets, you should uncheck the Truncate checkbox.
Cloning generators sets and copying generator specifications
Specifying different generators on a lot of columns and tables can be time consuming. Luckily you can easily clone generation sets that you can than change for a different purpose. Select the generation set and click the Clone generation set button. Each table and their generator properties are copied to the cloned generator set. Make sure to update the primary key columns to prevent duplicate keys.
There is also an option to copy the generator specification of a table or column and paste it in a different generator set. Right click a table or column and select Copy generator specification, then right click a target table or column and click Paste generator specification. If you copy the complete generator specification of a table, the table on which you can paste it should contain the exact same columns. Otherwise the paste option is greyed out.
Foreign Key
There are different methods to fill foreign key values! You can choose a constant if you want to refer to a specific value in the parent table. In that case you have to make sure that the referring key is present in that table. The Foreign Key generator however uses a lookup to actually get values from the parent table. There are two possible scenarios;
The parent table is part of the same generation set; in this case keys are generated that refer to the new parent records generated in the same generation set
The parent table is not part of the same generation set; in this case keys will be generated using current data content in the parent table
Random versus Deterministic Masking
All generators that use seed lists (for example; First name, Last name, Company, Job, User-Defined), can be randomly or deterministic replace the original values. When replacing original values in Random mode, each value will be replaced with a random value from the seed list. When the Replace the same original values with the same generated value is checked, it will make sure that multiple occurrences of the same original value, will be randomly replaced with the same seed value.
In Deterministic Mode each occurrence of the original value will be replaced consistently with the same value. Each time that you execute the masking template the value will be masked consistently. When masking for example names in Oracle and SQL Server with different templates, you can achieve consistent results by using the same seed list(language), generator salt and global salt without the use of any translation tables.
If you change the global salt in the Deployment - Settings this will affect all generators that are configured as deterministic. For each individual generator you can also specify a separate salt.
About Generators
The Generator options displayed in the drop-down list will reflect the datatype of the column in focus for masking. For instance, you cannot generate a “First Name“ value for an integer column, or generate a sequential number for a date-time column.
Standard Generator Functions
The available generators as provided by Privacy differ slightly based on the data type of the underlying column. Because there are (database specific) variations on data types, we’ll be grouping these together in a few groups. Strings(all data types focusing around text, from varchar fields to BLOBs), numerical and date & time data types.
Function name | Supported Data Types | Description |
|---|---|---|
Constant Value | String, Numerical, Date & Time | Creates a constant value in the generated dataset that is identical for every row. I.e. inputting MyFavoriteValue here will generate ‘MyFavoriteValue’ for every row in the resulting column’s dataset. |
Random Date/Time | String, Date & Time | Generates a random Date/Time value per row between a specified minimum and maximum datetime that corresponds with the underlying column’s datatype. |
Sequential Date/Time | String, Date & Time | Identical to the Random Date/Time generator except that this generator creates a sequential datetime for every row. Supplying a maximum datetime is optional. A number to increment the starting date is required, and can only accept whole numbers. Any unit of time to increment by can be chosen, from seconds to years. |
Random Decimal Number | String, Numerical (except for integer variants) | Generates a random decimal number between a supplied minimum and maximum value for every row. Using the Scale setting the decimal accuracy can be defined. For instance, a generator with a minimum value of 0 and a maximum value of 1000 using a scale of 4 might generate 132.4202. |
Random Whole Number | String, Numerical | Generates a random integer between a supplied minimum and maximum value for every row. |
Random String | String | Generates a random string of lower- and uppercase letters for every row. The minimum and maximum length for strings can be defined. |
Sequential Number | String, Numerical | Generates a sequential number for every row that starts at a specified value, and increments by the step value per row. Additionally, you can define a Padding for your generated integers. This is a set number that will be affixed to the generated integer. For example, using a padding of 3, and a start of 8 with a step of 2 will generate the following: 008 → 010 → 012 |
Names | String | The Names section contains multiple generators that generate data based on CSV files supplied by DATPROF. The available options are:
For some options (such as First Name) there are localization options which determine which CSV file is used. These can be toggled on/off with the language(s) drop-down menu. Multiple languages can be used simultaneously. |
2 Letter Country Code / 3 Letter Country Code | String | Generates a random country code per row either in a 2 letter country code, or a 3 letter country code format. |
City | String | Generates a random city name per row. Here, you can specify for which countries you’d like to generate random names using the Countries drop-down menu. |
Country | String | Generates a random country name per row. The Language(s) option specifies in which language the country will be written. Multiple options can be enabled simultaneously. |
Street | String | Generates a random existing street name per row. The Countries option allows you to specify for which country street names will be generated. |
A-Number / GBA number (Dutch township security number) | String, Numerical | Generates a 10 digit GBA number per row. |
BSN | String, Numerical | Generates a valid Dutch social security number per row. |
Color | String | Generates a random color per row. (Ex. Baby Blue, Sky Blue, Soft White) |
Color Code | String | Generates a color hexcode (Both three-digit shorthand and six-digit full length hexcodes) per row. |
Credit Card Account Number | String, Numerical | Generates a random credit card account number. Using Issuer(s), you must define one or multiple issuers to determine which syntax the generated account numbers adhere to. |
Currency Code | String | Generates a three letter currency code for every row. |
Currency Symbol | String | Generates a currency code for every row. |
Genre | String | Generates a media genre for every row. |
IBAN (International Bank Account Number) | String | Generates a valid IBAN number for every row. Using Country Code(s) you can specify which country codes you’d like your resulting IBAN codes to use. |
Job / Profession | String | Generates a profession for every row. Using the Language(s) you can specify which language(s) you want your resulting job names generated in. |
Military Rank | String | Generates a military rank name for every row. Using Department(s) you can specify which branches of the armed forces you’d like to include in your resulting dataset. |
SSN (US Social Security Number) | String | Generates a SSN for every row. You can specify how you want to separate your resulting numbers. You can choose one of the following formats: None (Example: 101010101, 003122142) Dashed (Example: 101-01-0101, 003-12-2142) Spaced (Example: 101 01 0101, 003 12 2142) |
User agent | String | Generates browser user agents like Mozilla/4.0 (compatible; MSIE 5.13; Mac_PowerPC), Opera/8.53 (Windows NT 5.2; U; en) per row. |
Advanced Generator Functions
SQL Expression
The SQL expression generator is special in that it can use values from other columns. All other generators will generate it's values into a temporary table per generation set inside your database. The SQL expression on a column is used when the data in inserted back into the original table. That way a user can use the data that is generated in other columns. No dependency specification is required since SQL Expression rules will be the last to be applied to the table in focus.
Value from seed file
Sometimes you may wish to provide your own replacement data to the masking process. This could be because of language, country/region or specific business reasons. You can generate your own seed (User Specified) file and specify it using this technique. The generator will randomly source a row from the file for each row in the table which is qualified by the Condition clause.
Notes on Seed files
Seed files are generally saved as .txt files.
The Encoding must be explicitly specified. The rule default is UTF-8.
An empty row in the seed file will randomly populate the column in focus with an empty value.
Value from multi-column seed file
Generate data across multiple columns that should be consistent based upon a multi column seed file. For example; replace a city, postalcode and street based on correlated seed file containing addresses. You can map multiple columns of the table to the specified seed file. This file shouldn't contain headers and must be a comma separated (.CSV) file.
Generator expression
Combine different generators together with static text. Each generator can be referenced with the $ symbol. Entering the $ symbol in the expression editor will open a list of available generators. Pick one from the list; dependent upon the generator you will be presented with options to specifiy the generator paramaters.
Some examples are:
Email address | $random-regex(regex="[A-Z]{1}").$random-last-name("US")@$weighted-random-generator(values="gmail.com,http://hotmail.com ",weights="30,70") This will generate: P.Sabella@gmail.com, O.Veach@hotmail.com, R.Levy@hotmail.com, etc |
Generator | Generator expression syntax |
|---|---|
Random Date/Time | $datetime-generator(min="1970-01-01 00:00:01",max="2038-01-19 03:14:07",format="yyyy-MM-dd HH:mm:ss") |
Random decimal number | $random-decimal(min="0.0",max="1000",precision="0") |
Random whole number | $random-integer(min="0",max="1000") |
Random string | $random-string(min="5",max="20") |
Sequential number | $sequential-number-generator(start="0",step="1") |
Brand | $random-brand() |
Company | $random-company("NL","DE") |
Female first name | $random-first-name-female("IT","DA","DE") |
Male first name | $random-first-name-male("ES") |
Last name | $random-last-name("IT","DE","NL") |
2 letter country code | $country-code-2() |
3 letter county code | $country-code-3() |
City | $random-city("NL","DE","US") |
Country | $random-country("DE","FR","NL","US") |
Street | $random-street("DE","NL","US") |
A-Number/GBA Number | $gba-generator() |
BSN (Dutch Social Security Number) | $bsn-generator() |
Color | $random-color() |
Color code | $random-color-code() |
Credit Card account number | $credit-card-number(issuers="Maestro") |
Currency code | $random-currency-code() |
Currency symbol | $random-currency-symbol() |
Genre | $random-genre() |
IBAN | $iban-bic(countries="NL") |
Job / Profession | $random-job("US") |
SSN (US Social Security Number) | $ssn-generator() |
User Agent | $random-user-agent() |
Regular Expression | $random-regex(regex="[A-Z]{1}") |
Value from seed file | $random-seed-value(file="C:\file.csv",charset="UTF-8") |
Weighted list | $weighted-random-generator(values="F,M",weights="50,50") |
Regular expression
Generates values based upon a regular expression. Some examples are:
Title | Regular Expression |
|---|---|
Address Type Pick a random value from a list | Billing|Delivery|Home|Office|Primary|Shipping |
Dutch Postal Code 3067ZG, 9372ED, 8423BE | [1-9][0-9]{3}[A-Z]{2} |
US Zip Code 48357/4986 , 19414, 21237-6415 | [0-9]{5}([- /]?[0-9]{4})? |
IP address 250.171.5.8, 4.8.5.180, 91.252.251.253 | ((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9]) |
For a full specification of the regular expression possibilities, check https://www.brics.dk/automaton/doc/index.html
Weighted list
Generates values based on user specified, comma separated, values. The weights parameter is a comma separated list which gives each value a proportional weighting. For example:
Values: Male, Female
Weights: 60, 40
In this case 60% of the values that are generated are Male and 40% of the generated values are Female.
Generator settings
Post SQL Expressions
You can further modify data on a generator set by filling in the Post SQL text box on any generator function. This expression will trigger after a field has been generated, and can be used to further customize the generated data. You can also reference different fields in the table and use them in the expression here. In terms of functionality, the syntax is identical to regular SQL Expressions.
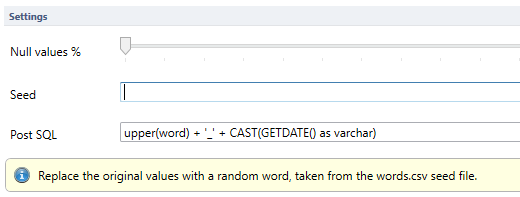
In this example we use the “Random Word” generator on our field named “word”. An expected result for this query could be “Magnanimous_04-10-2022”
Generator Seed
If you generate data, and need the data to be identical upon later execution, you can specify a seed value. Doing this will ensure that whenever you run this generator set again, your data will be identical. This can be useful if changing data can impact testing in a negative way. However, if you intend to execute a template multiple times on the same dataset, duplicate data will be generated.
Null Values %
Using this setting you can seed a percentage of NULL values into your resulting dataset.
Having NULL values can be an important part of testing, as missing data occurs regularly in production databases. However, if you specify a field as having a NOT NULL constraint in the database, attempting to seed NULL values in the resulting dataset will cause a run to fail.