Which character set codes can I use for my seed files?
When using Privacy, some functions allow you to supply a seed file. This is a file that contains multiple records from which usually random records are pulled to anonymize data. Because your database and the seed files used may be configured to use a non-Unicode character set, it’s possible to indicate which character set your seed file is encoded in. In general, any character set should be supported.
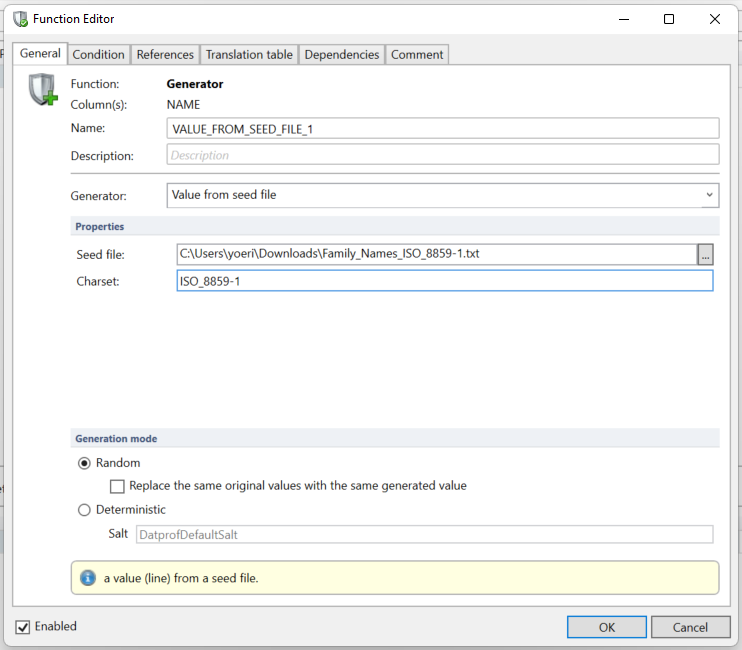
This function masks existing family names with random family names from a seed file encoded in ISO 8859 part 1.
Some databases archetype (such as Oracle) construct their own charset names and will display these when queried for. These are compound names, and thus not the same as what your OS uses. These cannot be supplied to Privacy directly.

So how do I supply character codes?
Use Windows/Linux standard annotations for character sets, i.e.:
For the Japanese 16-bit Shifted Japanese Industrial Standard use either SJIS or Shift-JIS. If you are uncertain about which annotation to use, open your seed file in a text editor like Notepad++ to determine the encoding. You should be able to copy this over one-on-one, as long as you replace any spaces with the underscore symbol ( _ ).