Is it possible to skip the source table row counting in Subset?
At the beginning of a Subset run, the row counts for the source and target tables are calculated to provide insight into the impact of the run. For example, if the source table has 1,200,000 rows and the target table has 12,000, we can determine that the final ratio is 10%. This counting process takes some time at the start of a run. Is it possible to disable this feature to speed up execution?
Resolution
In Subset it’s not possible to turn this off, however if the Subset package has been imported into Runtime you can. The reason we’ve decided to separate it this way is because usually when developing a template knowing how much a dataset is being subsetted is important for knowing whether the desired results are being reached. However, once a template has been implemented in Runtime we can safely assume that a run will perform according to expectations, and this overhead can be removed.
To do this, follow these steps:
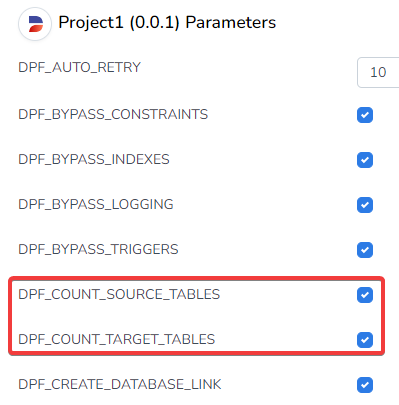
Runtime → Groups → Environment → Settings → Disable DPF_COUNT_SOURCE_TABLES and DPF_COUNT_TARGET_TABLES